10.6 其他Hadoop调度器介绍
1.自适应调度器
自适应调度器(Adaptive Scheduler)[1]是一种以用户期望运行时间为目标的调度器。该调度器根据每个作业会被分解成多个任务的事实,通过已经运行完成的任务的运行时间估算剩余任务的运行时间,进而使得该调度器能够根据作业的进度和剩余时间动态地为作业分配资源,以期望作业在规定时间内运行完成。
2.自学习调度器
自学习调度器(Learning Scheduler)[2]是一种基于贝叶斯分类算法的资源感知调度器。与现有的调度器不同,它更适用于异构Hadoop集群。该调度器的创新之处是将贝叶斯分类算法应用到MapReduce调度器设计中。
该调度器选取了若干个作业特征(用向量表示)作为分类属性,主要有作业平均CPU利用率、平均网络利用率、平均磁盘I/O利用率和平均内存利用率等。这些属性值可通过一个离线系统获取。调度器通过用户标注好的一些作业可训练得到一个分类器,这样,当某个TaskTracker出现剩余资源时,会通过心跳向JobTracker请求新的任务,同时汇报所在节点的资源使用信息。调度器收到该信息后,会将所有作业的特征向量作为贝叶斯分类器的输入,判断出当前哪些作业可在该TaskTracker上运行(称为“good”作业),哪些不可以在该TaskTracker上运行(称为“bad”作业),最后通过一个效用函数从所有“good”作业中选出一个最合适的作业。
3.动态优先级调度器
在0.21.X/0.22.X版本中,Hadoop引入了一个新的调度器——动态优先级调度器(Dynamic Priority Scheduler)[3]。该调度器允许用户动态调整自己获取的资源量以满足其服务质量要求。
该调度器试图把Hadoop集群看作一个提供商品的买卖市场,每个消费者有一定的预算购买自己需要的东西,且消费者需为购买某件商品竞标,其中,出价高的人可获得较多的商品,反之,出价少的人获得的商品也少。由于市场中商品价格是不断上下波动的,因此消费者可结合自己的需要调整自己的价位以买入更多或者更少的产品。对应到Hadoop集群中,slot是进行买卖的商品,Hadoop用户是消费者,每个用户分配有一定的预算,在任何一个阶段,可能有多个用户同时向Hadoop集群申请资源,其中出价高的用户获得的资源多,且申请资源的用户越多,单个slot的价位也就越高。
动态优先级调度器的核心思想是在一定的预算约束下,根据用户提供的消费率按比例分配资源。管理员可根据集群资源总量为每个用户分配一定的预算和一个时间单元的长度(通常为10s~1min),而用户可根据自己的需要动态调整自己的消费率,即每个时间单元内单个slot的价钱。在每个时间单元内,调度器按照以下步骤计算每个用户获得的资源量:
1)计算所有用户的消费率之和p。
2)对于每个用户i,分配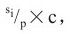 其中,si为用户i的消费率,c为Hadoop集群中slot总数。
其中,si为用户i的消费率,c为Hadoop集群中slot总数。
3)对于每个用户i,从其预算中扣除si×ui,其中ui为用户正在使用的slot数目。
动态优先级调度器也可作为一个元调度器集成到其他调度器(比如FIFO, Fair Scheduler等)中,这样,每个队列或者用户的可用资源量直接由动态优先级调度器动态计算得到,而其他调度器只需负责分配资源即可。相比于其他调度器,动态优先级调度器允许用户根据需要(比如完成时间)动态调整资源,进而可以对作业运行质量进行精细的控制。
[1]https://issues. apache.org/jira/browse/MAPREDUCE-1380
[2]https://issues. apache.org/jira/browse/MAPREDUCE-1439
[3]Thomas Sandholm and Kevin Lai. Dynamic proportional share scheduling in hadoop.In JSSPP'10:15th Workshop on Job Scheduling Strategies for Parallel Processing,2010
