3.3 Java API解析
Hadoop的主要编程语言是Java,因而Java API是最基本的对外编程接口。当前各个版本的Hadoop均同时存在新旧两种API。本节将对比讲解这两种API的设计思路,主要内容包括使用实例、接口设计、在MapReduce运行时环境中的调用时机等。
3.3.1 作业配置与提交
1.Hadoop配置文件介绍
在Hadoop中,Common、HDFS和MapReduce各有对应的配置文件,用于保存对应模块中可配置的参数。这些配置文件均为XML格式且由两部分构成:系统默认配置文件和管理员自定义配置文件。其中,系统默认配置文件分别是core-default.xml、hdfs-default.xml和mapred-default.xml,它们包含了所有可配置属性的默认值。而管理员自定义配置文件分别是core-site.xml、hdfs-site.xml和mapred-site.xml。它们由管理员设置,主要用于定义一些新的配置属性或者覆盖系统默认配置文件中的默认值。通常这些配置一旦确定,便不能被修改(如果想修改,需重新启动Hadoop)。需要注意的是,core-default.xml和core-site.xml属于公共基础库的配置文件,默认情况下,Hadoop总会优先加载它们。
在Hadoop中,每个配置属性主要包括三个配置参数:name、value和description,分别表示属性名、属性值和属性描述。其中,属性描述仅仅用来帮助用户理解属性的含义,Hadoop内部并不会使用它的值。此外,Hadoop为配置文件添加了两个新的特性:final参数和变量扩展。
❑final参数:如果管理员不想让用户程序修改某些属性的属性值,可将该属性的final参数置为true,比如:
<property>
<name>mapred.map.tasks.speculative.execution</name>
<value>true</value>
<final>true</final>
</property>
管理员一般在XXX-site.xml配置文件中为某些属性添加final参数,以防止用户在应用程序中修改这些属性的属性值。
❑变量扩展:当读取配置文件时,如果某个属性存在对其他属性的引用,则Hadoop首先会查找引用的属性是否为下列两种属性之一。如果是,则进行扩展。
〇其他已经定义的属性。
〇Java中System.getProperties()函数可获取属性。
比如,如果一个配置文件中包含以下配置参数:
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-${user.name}</value>
</property>
<property>
<name>mapred.temp.dir</name>
<value>${hadoop.tmp.dir}/mapred/temp</value>
</property>
则当用户想要获取属性mapred.temp.dir的值时,Hadoop会将hadoop.tmp.dir解析成该配置文件中另外一个属性的值,而user.name则被替换成系统属性user.name的值。
2.MapReduce作业配置与提交
在MapReduce中,每个作业由两部分组成:应用程序和作业配置。其中,作业配置内容包括环境配置和用户自定义配置两部分。环境配置由Hadoop自动添加,主要由mapred-default.xml和mapred-site.xml两个文件中的配置选项组合而成;用户自定义配置则由用户自己根据作业特点个性化定制而成,比如用户可设置作业名称,以及Mapper/Reducer、Reduce Task个数等。在新旧两套API中,作业配置接口发生了变化,首先通过一个例子感受一下使用上的不同。
旧API作业配置实例:
JobConf job=new JobConf(new Configuration(),MyJob.class);
job.setJobName("myjob");
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
JobClient.runJob(job);
新API作业配置实例:
Configuration conf=new Configuration();
Job job=new Job(conf,"myjob");
job.setJarByClass(MyJob.class);
job.setMapperClass(MyJob.MyMapper.class);
job.setReducerClass(MyJob.MyReducer.class);
System.exit(job.waitForCompletion(true)?0:1);
从以上两个实例可以看出,新版API用Job类代替了JobConf和JobClient两个类,这样,仅使用一个类的同时可完成作业配置和作业提交相关功能,进一步简化了作业编写方式。我们将在第5章介绍作业提交的相关细节,本小节重点从设计角度分析新旧两套API中作业配置的相关实现细节。
3.旧API中的作业配置
MapReduce配置模块代码结构如图3-6所示。其中,org.apache.hadoop.conf中的Configuration类是配置模块最底层的类。从图3-6中可以看出,该类支持以下两种基本操作。
❑序列化:序列化是将结构化数据转换成字节流,以便于传输或存储。Java实现了自己的一套序列化框架。凡是需要支持序列化的类,均需要实现Writable接口。
❑迭代:为了方便遍历所有属性,它实现了Java开发包中的Iterator接口。
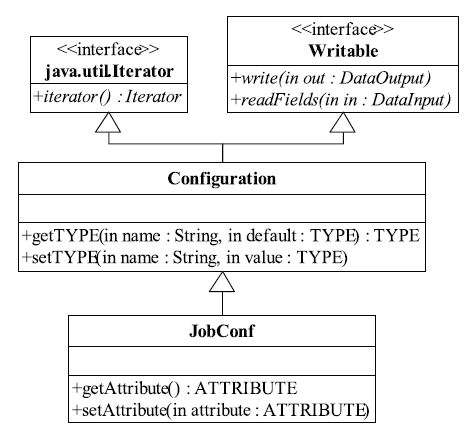
图 3-6 旧MapReduce API中作业配置类图
Configuration类总会依次加载core-default.xml和core-site.xml两个基础配置文件,相关代码如下:
addDefaultResource("core-default.xml");
addDefaultResource("core-site.xml");
addDefaultResource函数的参数为XML文件名,它能够将XML文件中的name/value加载到内存中。当连续调用多次该函数时,对于同一个配置选项,其后面的值会覆盖前面的值。
Configuration类中有大量针对常见数据类型的getter/setter函数,用于获取或者设置某种数据类型属性的属性值。比如,对于float类型,提供了这样一对函数:
float getFloat(String name, float defaultValue)
void setFloat(String name, float value)
除了大量getter/setter函数外,Configuration类中还有一个非常重要的函数:
void writeXml(OutputStream out)
该函数能够将当前Configuration对象中所有属性及属性值保存到一个XML文件中,以便于在节点之间传输。这点在以后的几节中会提到。
JobConf类描述了一个MapReduce作业运行时需要的所有信息,而MapReduce运行时环境正是根据JobConf提供的信息运行作业的。
JobConf继承了Configuration类,并添加了一些设置/获取作业属性的setter/getter函数,以方便用户编写MapReduce程序,如设置/获取Reduce Task个数的函数为:
public int getNumReduceTasks(){return getInt("mapred.reduce.tasks",1);}
public void setNumReduceTasks(int n){setInt("mapred.reduce.tasks",n);}
JobConf中添加的函数均是对Configuration类中函数的再次封装。由于它在这些函数名中融入了作业属性的名字,因而更易于使用。
默认情况下,JobConf会自动加载配置文件mapred-default.xml和mapred-site.xml,相关代码如下:
static{
Configuration.addDefaultResource("mapred-default.xml");
Configuration.addDefaultResource("mapred-site.xml");
}
4.新API中的作业配置
前面提到,与新API中的作业配置相关的类是Job。该类同时具有作业配置和作业提交的功能,其中,作业提交将在第5章中介绍,这里只关注作业配置部分。作业配置部分的类图如图3-7所示。Job类继承了一个新类JobContext,而Context自身则包含一个JobConf类型的成员。注意,JobContext类仅提供了一些getter方法,而Job类中则提供了一些setter方法。
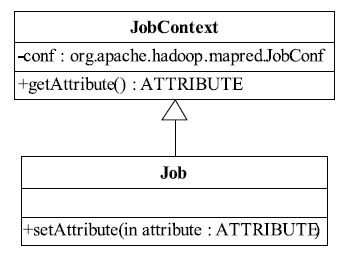
图 3-7 新MapReduce API中作业配置类图
