9.2.4 Hadoop参数调优
1.合理规划资源
(1)设置合理的槽位数目
在Hadoop中,计算资源是用槽位(slot)表示的。slot分为两种:Map slot和Reduce slot。每种slot代表了一定量的资源,且同种slot(比如Map slot)是同质的,也就是说,同种slot代表的资源量是相同的。管理员需根据实际需要为TaskTracker配置一定数目的Map slot和Reduce slot数目,从而限制每个TaskTracker上并发执行的Map Task和Reduce Task数目。
槽位数目是在各个TaskTracker上的mapred-site.xml中配置的,具体如表9-1所示。

(2)编写健康监测脚本
Hadoop允许管理员为每个TaskTracker配置一个节点健康状况监测脚本[1]。TaskTracker中包含一个专门的线程周期性执行该脚本,并将脚本执行结果通过心跳机制汇报给JobTracker。一旦JobTracker发现某个TaskTracker的当前状况为“不健康”(比如内存或者CPU使用率过高),则会将其加入黑名单,从此不再为它分配新的任务(当前正在执行的任务仍会正常执行完毕),直到该脚本执行结果显示为“健康”。健康监测脚本的编写和配置的具体方法,可参考7.3.1节。
需要注意的是,该机制只有Hadoop 0.20.2以上版本中有。
2.调整心跳配置
(1)调整心跳间隔
TaskTracker与JobTracker之间的心跳间隔大小应该适度。如果太小,JobTracker需要处理高并发的心跳信息,势必造成不小的压力;如果太大,则空闲的资源不能及时通知JobTracker(进而为之分配新的Task),造成资源空闲,进而降低系统吞吐率。对于中小规模(300个节点以下)的Hadoop集群,缩短TaskTracker与JobTracker之间的心跳间隔可明显提高系统吞吐率。
在Hadoop 1.0以及更低版本中,当节点集群规模小于300个节点时,心跳间隔将一直是3秒(不能修改)。这意味着,如果你的集群有10个节点,那么JobTracker平均每秒只需处理3.3(10/3=3.3)个心跳请求;而如果你的集群有100个节点,那么JobTracker平均每秒也只需处理33个心跳请求。对于一台普通的服务器,这样的负载过低,完全没有充分利用服务器资源。综上所述,对于中小规模的Hadoop集群,3秒的心跳间隔过大,管理员可根据需要适当减小心跳间隔[2],具体配置如表9-2所示。

(2)启用带外心跳
通常而言,心跳是由各个TaskTracker以固定时间间隔为周期发送给JobTracker的,心跳中包含节点资源使用情况、各任务运行状态等信息。心跳机制是典型的pull-based模型。TaskTracker周期性通过心跳向JobTracker汇报信息,同时获取新分配的任务。这种模型使得任务分配过程存在较大延时:当TaskTracker出现空闲资源时,它只能通过下一次心跳(对于不同规模的集群,心跳间隔不同,比如1 000个节点的集群,心跳间隔为10秒钟)告诉JobTracker,而不能立刻通知它。为了减少任务分配延迟,Hadoop引入了带外心跳(out-of-band heartbeat)[3]。带外心跳不同于常规心跳,它是任务运行结束或者任务运行失败时触发的,能够在出现空闲资源时第一时间通知JobTracker,以便它能够迅速为空闲资源分配新的任务。带外心跳的配置方法如表9-3所示。

3.磁盘块配置
Map Task中间结果要写到本地磁盘上,对于I/O密集型的任务来说,这部分数据会对本地磁盘造成很大压力,管理员可通过配置多块磁盘缓解写压力。当存在多块可用磁盘时,Hadoop将采用轮询的方式将不同Map Task的中间结果写到这些磁盘上,从而平摊负载,具体配置如表9-4所示。

4.设置合理的RPC Handler和HTTP线程数目
(1)配置RPC Handler数目
JobTracker需要并发处理来自各个TaskTracker的RPC请求,管理员可根据集群规模和服务器并发处理能够调整RPC Handler数目,以使JobTracker服务能力最佳,配置方法如表9-5所示。

(2)配置HTTP线程数目
在Shuffle阶段,Reduce Task通过HTTP请求从各个TaskTracker上读取Map Task中间结果,而每个TaskTracker通过Jetty Server处理这些HTTP请求。管理员可适当调整Jetty Server的工作线程数以提高Jetty Server的并发处理能力,具体如表9-6所示。

5.慎用黑名单机制
当一个作业运行结束时,它会统计在各个TaskTracker上失败的任务数目。如果一个TaskTracker失败的任务数目超过一定值,则作业会将它加到自己的黑名单中。如果一个TaskTracker被一定数目的作业加入黑名单,则JobTracker会将该TaskTracker加入系统黑名单,此后JobTracker不再为其分配新的任务,直到一定时间段内没有出现失败的任务。
当Hadoop集群规模较小时,如果一定数量的节点被频繁加入系统黑名单中,则会大大降低集群吞吐率和计算能力,因此建议关闭该功能,具体配置方法可参考6.5.2小节。
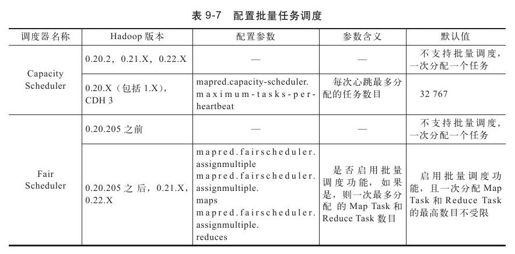
6.启用批量任务调度
在Hadoop中,调度器是最核心的组件之一,它负责将系统中空闲的资源分配给各个任务。当前Hadoop提供了多种调度器,包括默认的FIFO调度器、Fair Scheduler、Capacity Scheduler等,调度器的调度效率直接决定了系统的吞吐率高低。通常而言,为了将空闲资源尽可能分配给任务,Hadoop调度器均支持批量任务调度[4],即一次将所有空闲任务分配下去,而不是一次只分配一个,具体配置如表9-7所示(FIFO调度器本身就是批量调度器)。
7.选择合适的压缩算法
Hadoop通常用于处理I/O密集型应用。对于这样的应用,Map Task会输出大量中间数据,这些数据的读写对用户是透明的,如果能够支持中间数据压缩存储,则会明显提升系统的I/O性能。当选择压缩算法时,需要考虑压缩比和压缩效率两个因素。有的压缩算法有很好的压缩比,但压缩/解压缩效率很低;反之,有一些算法的压缩/解压缩效率很高,但压缩比很低。因此,一个优秀的压缩算法需平衡压缩比和压缩效率两个因素。
当前有多种可选的压缩格式,比如gzip、zip、bzip2、LZO[5]、Snappy[6]等,其中,LZO和Snappy在压缩比和压缩效率两方面的表现都比较优秀。其中,Snappy是Google开源的数据压缩库,它的编码/解码器已经内置到Hadoop 1.0以后的版本中[7];LZO则不同,它是基于GPL许可的,不能通过Apache来分发许可,因此,它的Hadoop编码/解码器必须单独下载[8]。
下面以Snappy为例介绍如何让Hadoop压缩Map Task中间输出数据结果(在mapred-site.xml中配置):
<property>
<name>mapred.compress.map.output</name>
<value>true</value>
</property>
<property>
<name>mapred.map.output.compression.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
其中,“mapred.compress.map.output”表示是否要压缩Map Task中间输出结果,“mapred.map.output.compression.codec”表示采用的编码/解码器。
表9-8显示了Hadoop各版本是否内置了Snappy压缩算法。

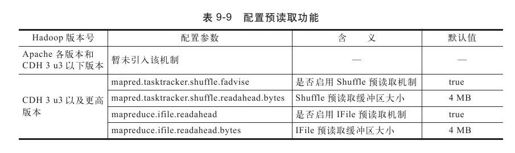
8.启用预读取机制
前面提到,预读取机制可以有效提高磁盘的I/O读性能。由于Hadoop是典型的顺序读系统,采用预读取机制可明显提高HDFS读性能和MapReduce作业执行效率。管理员可为MapReduce的数据拷贝和IFile文件读取启用预读取功能[9],具体如表9-9所示。
[1]https://issues. apache.org/jira/browse/MAPREDUCE-211
[2]https://issues. apache.org/jira/browse/MAPREDUCE-1906
[3]https://issues. apache.org/jira/browse/MAPREDUCE-2355
[4]https://issues. apache.org/jira/browse/HADOOP-3136
[5]http://www. oberhumer.com/opensource/lzo/
[6]http://code. google.com/p/snappy/
[7]https://issues. apache.org/jira/browse/HADOOP-7206
[8]https://github. com/toddlipcon/hadoop-lzo
[9]https://issues. apache.org/jira/browse/HADOOP-7714
