5.2.3 产生InputSplit文件
用户提交MapReduce作业后,JobClient会调用InputFormat的getSplits方法生成InputSplit相关信息。该信息包括两部分:InputSplit元数据信息和原始InputSplit信息。其中,第一部分将被JobTracker使用,用以生成Task本地性(Task Locality)相关的数据结构;而第二部分则将被Map Task初始化时使用,用以获取自己要处理的数据。这两部分信息分别被保存到目录${mapreduce.jobtracker.staging.root.dir}/${user}/.staging/${JobId}下的文件job.split和job.splitmetainfo中。
InputSplit相关操作放在包org.apache.hadoop.mapreduce.split中,主要包含三个类JobSplit、JobSplitWriter和SplitMetaInfoReader。它们的关系如图5-5所示。
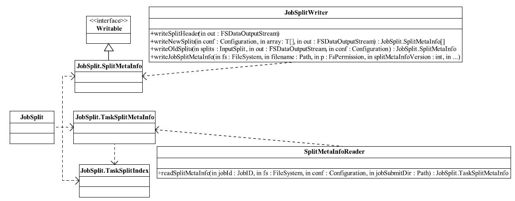
图 5-5 InputSplit类关系图
JobSplit封装了读写InputSplit相关的基础类,主要包括以下三个。
❑SplitMetaInfo:描述一个InputSplit的元数据信息,包括以下三项内容:
private long startOffset;//该InputSplit元信息在job.split文件中的偏移量
private long inputDataLength;//该InputSplit的数据长度
private String[]locations;//该InputSplit所在的host列表
所有InputSplit对应的SplitMetaInfo将被保存到文件job.splitmetainfo中。该文件内容组织方式如图5-6所示,内容依次为:一个用于标识InputSplit元数据文件头部的字符串“META-SP”,文件版本号splitVersion(当前值是1),作业对应的InputSplit数目length,最后是length个InputSplit对应的SplitMetaInfo信息。

图 5-6 job.splitmetainfo文件内容组织方式
作业在JobTracker端初始化时,需读取job.splitmetainfo文件创建Map Task,具体参考5.3节。
❑TaskSplitMetaInfo:用于保存InputSplit元信息的数据结构,包括以下三项内容:
private TaskSplitIndex splitIndex;//Split元信息在job.split文件中的位置
private long inputDataLength;//InputSplit的数据长度
private String[]locations;//InputSplit所在的host列表
这些信息是在作业初始化时,JobTracker从文件job.splitmetainfo中获取的。其中,host列表信息是任务调度器判断任务是否具有本地性的最重要因素,而splitIndex信息保存了新任务需处理的数据位置信息在文件job.split中的索引,TaskTracker(从JobTracker端)收到该信息后,便可以从job.split文件中读取InputSplit信息,进而运行一个新任务。
❑TaskSplitIndex:JobTracker向TaskTracker分配新任务时,TaskSplitIndex用于指定新任务待处理数据位置信息在文件job.split中的索引,主要包括两项内容:
private String splitLocation;//job.split文件的位置(目录)
private long startOffset;//InputSplit信息在job.split文件中的位置
