6.7.2 任务选择策略分析
任务选择发生在调度器选定一个作业之后,目的是从该作业中选择一个最合适的任务。在Hadoop中,选择Map Task时需考虑的最重要的因素是数据本地性,也就是尽量将任务调度到数据所在节点。除了数据本地性之外,还需考虑失败任务、备份任务的调度顺序等。然而,由于Reduce Task没有数据本地性可言,因此选择Reduce Task时通常只需考虑未运行任务和备份任务的调度顺序。
(1)数据本地性
在分布式环境中,为了减少任务执行过程中的网络传输开销,通常将任务调度到输入数据所在的计算节点,也就是让数据在本地进行计算,而Hadoop正是以“尽力而为”的策略保证数据本地性的。
为了实现数据本地性,Hadoop需要管理员提供集群的网络拓扑结构。如图6-13所示,Hadoop集群采用了三层网络拓扑结构,其中,根节点表示整个集群,第一层代表数据中心,第二层代表机架或者交换机,第三层代表实际用于计算和存储的物理节点。对于目前的Hadoop各个版本而言,默认均采用了二层网络拓扑结构,即数据中心一层暂时未被考虑。
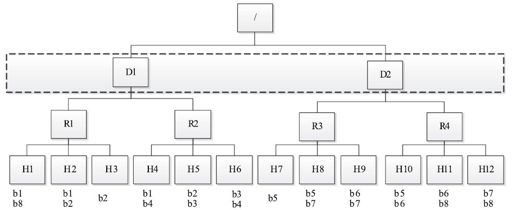
图 6-13 Hadoop网络拓扑结构图
Hadoop根据输入数据与实际分配的计算资源之间的距离将任务分成三类:node-local(输入数据与计算资源同节点),rack-local(同机架)和off-switch(跨机架)。当输入数据与计算资源位于不同节点上时,Hadoop需将输入数据远程复制到计算资源所在节点进行处理。两者距离越远,需要的网络开销越大,因此调度器进行任务分配时尽量选择离输入数据近的节点资源。
当Hadoop进行任务选择时,采用了自下向上查找的策略。由于当前采用了两层网络拓扑结构,因此这种选择机制决定了任务优先级从高到低依次为:node-local、rack-local和off-switch。下面结合图6-13介绍三种类型的任务被选中的场景。
假设某一时刻,TaskTracker X出现空闲的计算资源,向JobTracker汇报心跳请求新的任务,调度器根据一定的调度策略为之选择了任务Y。
场景1 如果X是H1,任务Y输入数据块为b1,则该任务为node-local。
场景2 如果X是H1,任务Y输入数据块为b2,则该任务为rack-local。
场景3 如果X是H1,任务Y输入数据块为b4,则该任务为off-switch。
(2)Map Task选择策略
用户追踪作业运行状态的JobInProgress对象为Map Task维护了五个数据结构:
//Node与未运行的TIP集合映射关系,通过作业的InputFormat可直接获取的
Map<Node, List<TaskInProgress>>nonRunningMapCache;
//Node与运行的TIP集合映射关系,一个任务获得调度机会,其TIP便会添加进来
Map<Node, Set<TaskInProgress>>runningMapCache;
//non-local且未运行的TIP集合,non-local是指任务没有输入数据(InputSplit为空),//这可
能是一些计算密集型任务,比如Hadoop exmaple中的PI作业
final List<TaskInProgress>nonLocalMaps;
//按照Task Attempt失败次数排序的TIP集合
final SortedSet<TaskInProgress>failedMaps;
//non-local且正在运行的TIP集合
Set<TaskInProgress>nonLocalRunningMaps;
当需要从作业中选择一个Map Task时,调度器会直接调用JobInProgress中的obtain-NewMapTask方法。该方法封装了所有调度器公用的任务选择策略实现。其主要思想是优先选择运行失败的任务,以让其快速获取重新运行的机会,其次是按照数据本地性策略选择尚未运行的任务,最后是查找正在运行的任务,尝试为“拖后腿”任务启动备份任务。具体步骤如下:
步骤1 合法性检查。如果一个作业在某个节点上失败任务数目超过一定阈值或者该节点剩余磁盘容量不足,则不再将该作业的任何任务分配给该节点。
步骤2 从failedMaps列表中选择任务。failedMaps保存了按照Task Attempt失败次数排序的TIP集合。失败次数越多的任务,被调度的机会越大。需要注意的是,为了让失败的任务快速得到重新运行的机会,在进行任务选择时不再考虑数据本地性。
步骤3 从nonRunningMapCache列表中选择任务。采用的任务选择方法完全遵循数据本地性策略,即任务选择优先级从高到低依次为node-local, rack-local和off-switch类型的任务。
步骤4 从nonLocalMaps列表中选择任务。由于nonLocalMaps中的任务没有输入数据,因此无须考虑数据本地性。
步骤5 从runningMapCache列表中选择任务。遍历runningMapCache列表,查找是否存在正运行且“拖后腿”的任务,如果有,则为其启动一个备份任务。
步骤6 从nonLocalRunningMaps列表中选择任务。同步骤5,从nonLocalRunningMaps列表中查找“拖后腿”任务,并为其启动备份任务。
步骤2~6中任何一个步骤中查找到一个合适的任务后则直接返回,不再进行下面的步骤。
(3)Reduce Task选择策略
由于Reduce Task不存在数据本地性,因此,与Map Task相比,它的调度策略显得非常简单。JobInProgress对象为其保存了两个数据结构:nonRunningReduces和runningReduces,分别表示尚未运行的TIP列表和正在运行的TIP列表。由此采用的任务选择步骤如下:
步骤1 合法性检查。同Map Task一样,对节点可靠性和磁盘空间进行检查。
步骤2 从nonRunningReduces列表中选择任务。无须考虑数据本地性,只需依次遍历该列表中的任务,选出第一个满足条件(未曾在对应节点上失败过)的任务。
步骤3 从runningReduces列表中选择任务,为“拖后腿”的任务启动备份任务。
