2.1.3 Hadoop版本变迁
到2012年5月为止,Apache Hadoop已经出现四个大的分支,如图2-1所示。
Apache Hadoop的四大分支构成了四个系列的Hadoop版本。
1.0.20.X系列
0.20.2版本发布后,几个重要的特性没有基于trunk而是在0.20.2基础上继续研发。值得一提的主要有两个特性:Append与Security。其中,含Security特性的分支以0.20.203版本发布,而后续的0.20.205版本综合了这两个特性。需要注意的是,之后的1.0.0版本仅是0.20.205版本的重命名。0.20.X系列版本是最令用户感到疑惑的,因为它们具有的一些特性,trunk上没有;反之,trunk上有的一些特性,0.20.X系列版本却没有。
2.0.21.0/0.22.X系列
这一系列版本将整个Hadoop项目分割成三个独立的模块,分别是Common、HDFS和MapReduce。HDFS和MapReduce都对Common模块有依赖性,但是MapReduce对HDFS并没有依赖性。这样,MapReduce可以更容易地运行其他分布式文件系统,同时,模块间可以独立开发。具体各个模块的改进如下。
❑Common模块:最大的新特性是在测试方面添加了Large-Scale Automated TestFramework[1]和Fault Injection Framework[2]。
❑HDFS模块:主要增加的新特性包括支持追加操作与建立符号连接、SecondaryNameNode改进(Secondary NameNode被剔除,取而代之的是Checkpoint Node,同时添加一个Backup Node的角色,作为NameNode的冷备)、允许用户自定义block放置算法等。
❑MapReduce模块:在作业API方面,开始启动新MapReduce API,但老的API仍然兼容。
0.22.0在0.21.0的基础上修复了一些bug并进行了部分优化。

图 2-1 Hadoop版本变迁图[3]
3.0.23.X系列
0.23.X是为了克服Hadoop在扩展性和框架通用性方面的不足而提出来的。它实际上是一个全新的平台,包括分布式文件系统HDFS Federation和资源管理框架YARN两部分,可对接入的各种计算框架(如MapReduce、Spark[4]等)进行统一管理。它的发行版自带MapReduce库,而该库集成了迄今为止所有的MapReduce新特性。
4.2.X系列
同0.23.X系列一样,2.X系列也属于下一代Hadoop。与0.23.X系列相比,2.X系列增加了NameNode HA和Wire-compatibility等新特性。
表2-1总结了Hadoop各个发布版的特性以及稳定性。
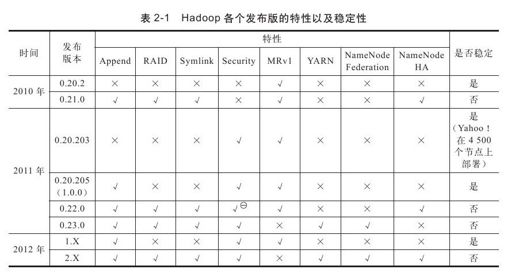
本书之所以以分析Apache Hadoop 1.0.0为主,主要是因为这是一个稳定的版本,再有其为1.0.0,具有里程碑意义。Apache发布这个版本,也是希望该版本成为业界的规范。需要注意的是,尽管本书以分析Apache Hadoop 1.0.0版本为主,但本书内容适用于所有Apache Hadoop 1.X版本[6]。
[1]参考https://issues.apache.org/jira/browse/HADOOP-6332
[2]参考http://hadoop.apache.org/hdfs/docs/r0.21.0/faultinject_framework.html
[3]图片修改自:http://www.cloudera.com/blog/2012/01/an-update-on-apache-hadoop-1-0/
[4]Spark是一种内存计算框架,支持迭代式计算,主页是http://www.spark-project.org/.
[5]0.22.0版本中只有HDFS Security,没有MapReduce Security。
[6]不同版本之间细节可能稍有不同,此时以Hadoop 1.0.0版本为主。
