3.3.4 Mapper与Reducer解析
1.旧版API的Mapper/Reducer解析
Mapper/Reducer中封装了应用程序的数据处理逻辑。为了简化接口,MapReduce要求所有存储在底层分布式文件系统上的数据均要解释成key/value的形式,并交给Mapper/Reducer中的map/reduce函数处理,产生另外一些key/value。
Mapper与Reducer的类体系非常类似,我们以Mapper为例进行讲解。Mapper的类图如图3-15所示,包括初始化、Map操作和清理三部分。
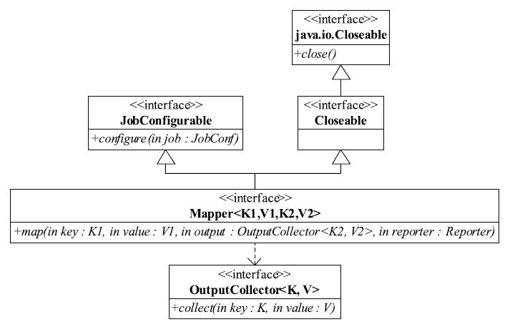
图 3-15 旧版API的Mapper类图
(1)初始化
Mapper继承了JobConfigurable接口。该接口中的configure方法允许通过JobConf参数对Mapper进行初始化。
(2)Map操作
MapReduce框架会通过InputFormat中RecordReader从InputSplit获取一个个key/value对,并交给下面的map()函数处理:
void map(K1 key, V1 value, OutputCollector<K2,V2>output, Reporter reporter)throws IOException;
该函数的参数除了key和value之外,还包括OutputCollector和Reporter两个类型的参数,分别用于输出结果和修改Counter值。
(3)清理
Mapper通过继承Closeable接口(它又继承了Java IO中的Closeable接口)获得close方法,用户可通过实现该方法对Mapper进行清理。
MapReduce提供了很多Mapper/Reducer实现,但大部分功能比较简单,具体如图3-16所示。它们对应的功能分别是:
❑ChainMapper/ChainReducer:用于支持链式作业,具体见3.5.2节。
❑IdentityMapper/IdentityReducer:对于输入key/value不进行任何处理,直接输出。
❑InvertMapper:交换key/value位置。
❑RegexMapper:正则表达式字符串匹配。
❑TokenMapper:将字符串分割成若干个token(单词),可用作WordCount的Mapper。
❑LongSumReducer:以key为组,对long类型的value求累加和。
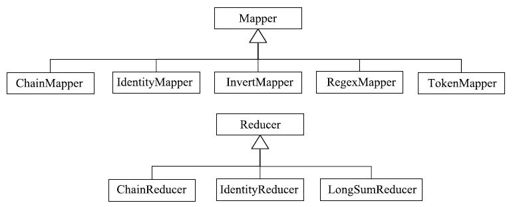
图 3-16 Hadoop MapReduce自带Mapper/Reducer实现的类层次图
对于一个MapReduce应用程序,不一定非要存在Mapper。MapReduce框架提供了比Mapper更通用的接口:MapRunnable,如图3-17所示。用户可以实现该接口以定制Mapper的调用方式或者自己实现key/value的处理逻辑,比如,Hadoop Pipes自行实现了MapRunnable,直接将数据通过Socket发送给其他进程处理。提供该接口的另外一个好处是允许用户实现多线程Mapper。
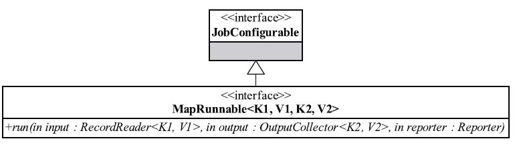
图 3-17 MapRunnable类图
如图3-18所示,MapReduce提供了两个MapRunnable实现,分别是MapRunner和MultithreadedMapRunner,其中MapRunner为默认实现。MultithreadedMapRunner实现了一种多线程的MapRunnable。默认情况下,每个Mapper启动10个线程,通常用于非CPU类型的作业以提供吞吐率。
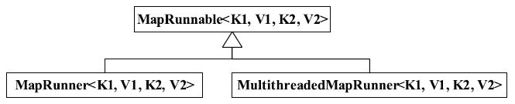
图 3-18 Hadoop MapReduce自带MapRunnable实现的类层次图
2.新版API的Mapper/Reducer解析
从图3-19可知,新API在旧API基础上发生了以下几个变化:
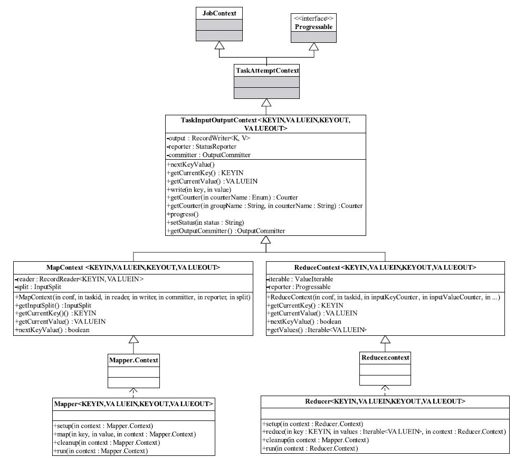
图 3-19 新版API的Mapper/Reducer类图
❑Mapper由接口变为抽象类,且不再继承JobConfigurable和Closeable两个接口,而是直接在类中添加了setup和cleanup两个方法进行初始化和清理工作。
❑将参数封装到Context对象中,这使得接口具有良好的扩展性。
❑去掉MapRunnable接口,在Mapper中添加run方法,以方便用户定制map()函数的调用方法,run默认实现与旧版本中MapRunner的run实现一样。
❑新API中Reducer遍历value的迭代器类型变为java.lang.Iterable,使得用户可以采用“foreach”形式遍历所有value,如下所示:
void reduce(KEYIN key, Iterable<VALUEIN>values, Context context
)throws IOException, InterruptedException{
for(VALUEIN value:values){//注意遍历方式
context.write((KEYOUT)key,(VALUEOUT)value);
}
}
