3.4 非Java API解析
3.4.1 Hadoop Streaming的实现原理
Hadoop Streaming是Hadoop为方便非Java用户编写MapReduce程序而设计的工具包。它允许用户将任何可执行文件或者脚本作为Mapper/Reducer,这大大提高了程序员的开发效率。
Hadoop Streaming要求用户编写的Mapper/Reducer从标准输入中读取数据,并将结果写到标准数据中,这类似于Linux中的管道机制。
1.Hadoop Streaming编程实例
以WordCount为例,可用C++分别实现Mapper和Reducer,具体方法如下(这里仅是最简单的实现,并未全面考虑各种异常情况)。
Mapper实现的具体代码如下:
int main(){//Mapper将会被封装成一个独立进程,因而需要有main()函数
string key;
while(cin>>key){//从标准输入流中读取数据
//输出中间结果,默认情况下TAB为key/value分隔符
cout<<key<<"\t"<<"1"<<endl;
}
return 0;
}
Reducer实现的具体代码如下:
int main(){//Reducer将会被封装成一个独立进程,因而需要有main()函数
string cur_key, last_key, value;
cin>>cur_key>>value;
last_key=cur_key;
int n=1;
while(cin>>cur_key){//读取Map Task输出结果
cin>>value;
if(last_key!=cur_key){//识别下一个key
cout<<last_key<<"\t"<<n<<endl;
last_key=cur_key;
n=1;
}else{//获取key相同的所有value数目
n++;//key值相同的,累计value值
}
}
return 0;
}
分别编译这两个程序,生成的可执行文件分别是wc_mapper和wc_reducer,并将它们和contrib/streaming/hadoop-streaming-1.0.0.jar一起复制到Hadoop安装目录下,使用以下命令提交作业:
$HADOOP_HOME/bin/hadoop jar$HADOOP_HOME/hadoop-streaming-1.0.0.jar\
-files wc_mapper, wc_reducer\
-input/test/intput\
-output/test/output\
-mapper wc_mapper\
-reducer wc_reducer
由于Hadoop Streaming类似于Linux管道,这使得测试变得非常容易。用户可直接在本地使用下面命令测试结果是否正确:
cat test.txt|./wc_mapper|sort|./wc_reducer
2.Hadoop Streaming实现原理分析
Hadoop Streaming工具包实际上是一个使用Java编写的MapReduce作业。当用户使用可执行文件或者脚本文件充当Mapper或者Reducer时,Java端的Mapper或者Reducer充当了wrapper角色,它们将输入文件中的key和value直接传递给可执行文件或者脚本文件进行处理,并将处理结果写入HDFS。
实现Hadoop Streaming的关键技术点是如何使用标准输入输出实现Java与其他可执行文件或者脚本文件之间的通信。为此,Hadoop Streaming使用了JDK中的java.lang.ProcessBuilder类。该类提供了一整套管理操作系统进程的方法,包括创建、启动和停止进程(也就是应用程序)等。相比于JDK中的Process类,ProcessBuilder允许用户对进程进行更多控制,包括设置当前工作目录、改变环境参数等。
下面分析Mapper的执行过程(Reducer的类似)。整个过程如图3-23所示,Hadoop Streaming使用ProcessBuilder以独立进程方式启动可执行文件wc_mapper,并创建该进程的输入输出流,具体实现代码如下:
……
//将wc_mapper封装成一个进程
ProcessBuilder builder=new ProcessBuilder("wc_mapper");
builder.environment().putAll(childEnv.toMap());//设置环境变量
sim=builder.start();
//创建标准输出流
clientOut_=new DataOutputStream(new BufferedOutputStream(
sim.getOutputStream(),
BUFFER_SIZE));
//创建标准输入流
clientIn_=new DataInputStream(new BufferedInputStream(
sim.getInputStream(),
BUFFER_SIZE));
//创建标准错误流
clientErr_=new DataInputStream(new
BufferedInputStream(sim.getErrorStream()));
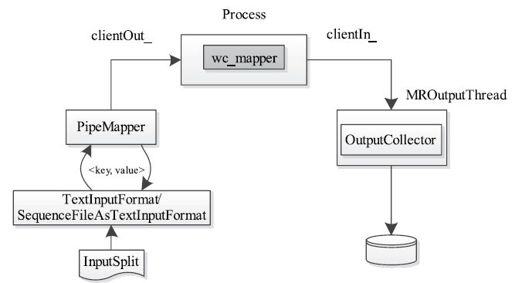
图 3-23 Hadoop Streaming工作原理图
Hadoop Streaming提供了一个默认的PipeMapper。它实际上是C++端Mapper的wrapper,主要作用是向已经创建好的输出流clientOut_中写入数据,具体实现代码如下:
public void map(Object key, Object value, OutputCollector output, Reporter
reporter)throws IOException{
……
clientOut_.write(key,0,keySize);
clientOut_.write(mapInputFieldSeparator);
clientOut_.write(value,0,valueSize);
clientOut_.write('\n');
}
写入clientOut的数据直接成为wc_mapper的输入,待数据被处理完后,可直接从标准输入流clientIn中获取结果:
//MROutputThread
public void run(){
lineReader=new LineReader((InputStream)clientIn,job);
while(lineReader.readLine(line)>0){
splitKeyVal(line, line.getLength(),key, val);
output.collect(key, val);
}
}
通过分析以上代码可知,由于Hadoop Streaming使用分隔符定位一个完整的key或value,因而只能支持文本格式数据,不支持二进制格式。在0.21.0/0.22.X系列版本中,Hadoop Streaming增加了对二进制文件的支持[1],并添加了两种新的二进制文件格式:RawBytes和TypedBytes。顾名思义,RawBytes指key和value是原始字节序列,而TypedBytes指key和value可以拥有的数据类型,比如boolean、list、map等。由于它们采用的是长度而不是某一种分隔符定位key和value,因而支持二进制文件格式。
RawBytes传递给可执行文件或者脚本文件的内容编码格式为:
<4 byte length><key raw bytes><4 byte length><value raw bytes>
TypedBytes允许用户为key和value指定数据类型。对于长度固定的基本类型,如byte、bool、int、long等,其编码格式为:
<1 byte type code><key bytes><1 byte type code><value bytes>
对于长度不固定的类型,如byte array、string等,其编码格式为:
<1 byte type code><4 byte length><key raw bytes><1 byte type code><4 byte length><value raw bytes>
当key和value大部分情况下为固定长度的基本类型时,TypedBytes比RawBytes格式更节省空间。
[1]https://issues. apache.org/jira/browse/HADOOP-1722
