3.4.2 Hadoop Pipes的实现原理
Hadoop Pipes是Hadoop为方便C/C++用户编写MapReduce程序而设计的工具。其设计思想是将应用逻辑相关的C++代码放在单独的进程中,然后通过Socket让Java代码与C++代码通信以完成数据计算。
1.编程实例
同样,以WordCount为例,采用C++分别编写Mapper和Reducer,具体方法如下。
Mapper实现的具体代码如下:
class WordCountMapper:public HadoopPipes:Mapper{//注意基类
public:
WordCountMapper(HadoopPipes:TaskContext&context){
//在此初始化,比如定义计数器等
}
//MapContext封装了Mapper的各种操作
void map(HadoopPipes:MapContext&context){
std:vector<std:string>words=
HadoopUtils:splitString(context.getInputValue(),"");
for(unsigned int i=0;i<words.size();++i){
context.emit(words[i],"1");//用emit输出key/value对
}
}
};
Reducer实现的具体代码如下:
class WordCountReducer:public HadoopPipes:Reducer{
public:
WordCountReducer(HadoopPipes:TaskContext&context){
}
//ReduceContext封装了Reducer的各种操作
void reduce(HadoopPipes:ReduceContext&context){
int sum=0;
while(context.nextValue()){//迭代获取该key对应的value列表
sum+=HadoopUtils:toInt(context.getInputValue());
}
context.emit(context.getInputKey(),HadoopUtils:toString(sum));
}
};
main()函数的具体实现代码如下:
//每个Hadoop Pipes作业将被单独封装成一个进程,因此需要有main()函数
int main(int argc, char*argv[]){
return HadoopPipes:runTask(
HadoopPipes:TemplateFactory<WordCountMap, WordCountReduce>());
}
编译之后生成可执行文件wordcount,输入以下命令运行作业:
bin/hadoop pipes\
-D hadoop.pipes.java.recordreader=true\
-D hadoop.pipes.java.recordwriter=true\
-D mapred.job.name=wordcount\
-input/test/intput\
-output/test/output\
-program wordcount
与Hadoop Streaming比较,可以发现,Hadoop Pipes的一个缺点是调试不方便。因为输入的数据是Java端代码通过Socket传到C++应用程序的,所以用户不能单独对C++部分代码进行测试,而需要连同Java端代码一起启动。
2.实现原理分析
Hadoop Pipes的实现原理与Hadoop Streaming非常类似,它也使用Java中的ProcessBuilder以单独进程方式启动可执行文件。不同之处是Java代码与可执行文件(或者脚本)的通信方式:Hadoop Streaming采用标准输入输出,而Hadoop Pipes采用Socket。
Hadoop Pipes由两部分组成:Java端代码和C++端代码。与Hadoop Streaming一样,Java端代码实际上实现了一个MapReduce作业,Java端的Mapper或者Reducer实际上是C++端Mapper或者Reducer的封装器(wrapper),它们通过Socket将输入的key和value直接传递给可执行文件执行。
Hadoop Pipes具体执行流程如图3-24所示。该序列图阐释了执行Mapper时,Java端与C++端通过Socket进行交互的过程,主要有以下几个步骤:
步骤1 用户提交Pipes作业后,Java端启动一个Socket server(等待C++端接入),同时以独立进程方式运行C++端代码。
步骤2 C++端以Client身份连接Java端的Socket server,连接成功后,Java端依次发送一系列指令通知C++端进行各项准备工作。
步骤3 Java端通过mapItem()函数不断向C++端传送key/value对,C++端将计算结果返回给Java端,Java端对结果进行保存。
步骤4 所有数据处理完毕后,Java端通知C++端终止计算,并关闭C++端进程。
上面分析了Java端与C++端的交互过程,接下来深入分析Hadoop Pipes内部实现原理。如图3-25所示,Java端用PipesMapRunner实现了MapRunner,在MapRunner内部,借助两个协议类DownwardProtocol和UpwardProtocol向C++端发送数据和从C++端接收数据,而C++端也有两个类与之对应,分别是Protocol和UpwardProtocol。Protocol将收到的数据传给用户编写的Mapper,经Mapper、Combiner和Partitioner处理后,由UpwardProtocol返回给Java端的UpwardProtocol,由它写到本地磁盘上。
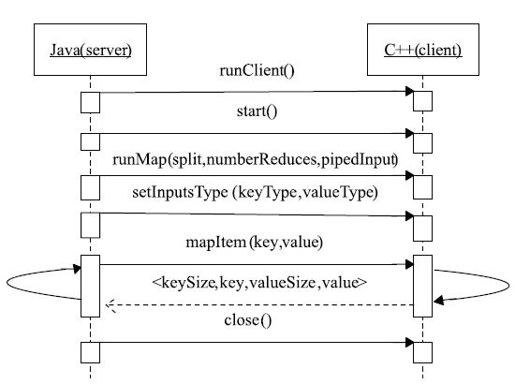
图 3-24 Hadoop Pipes中Java端与C++端交互序列图
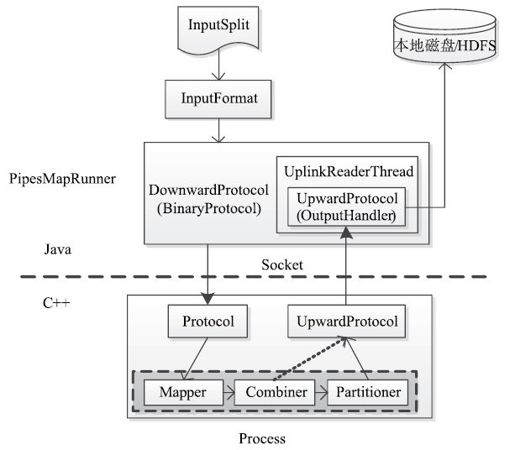
图 3-25 Hadoop Pipes内部实现原理图
