3.5.2 ChainMapper/ChainReducer的实现原理
ChainMapper/ChainReducer主要为了解决线性链式Mapper而提出的。也就是说,在Map或者Reduce阶段存在多个Mapper,这些Mapper像Linux管道一样,前一个Mapper的输出结果直接重定向到下一个Mapper的输入,形成一个流水线,形式类似于[MAP+REDUCE MAP*]。图3-27展示了一个典型的ChainMapper/ChainReducer的应用场景:在Map阶段,数据依次经过Mapper1和Mapper2处理;在Reduce阶段,数据经过shuffle和sort后;交由对应的Reducer处理,但Reducer处理之后并没有直接写到HDFS上,而是交给另外一个Mapper处理,它产生的结果写到最终的HDFS输出目录中。
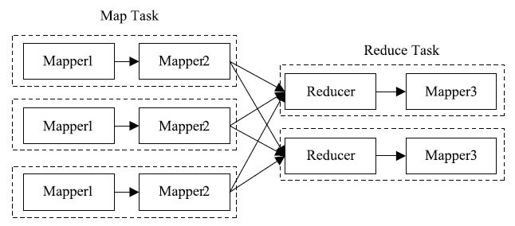
图 3-27 ChainMapper/ChainReducer应用实例
需要注意的是,对于任意一个MapReduce作业,Map和Reduce阶段可以有无限个Mapper,但Reducer只能有一个。也就是说,图3-28所示的计算过程不能使用ChainMapper/ChainReducer完成,而需要分解成两个MapReduce作业。
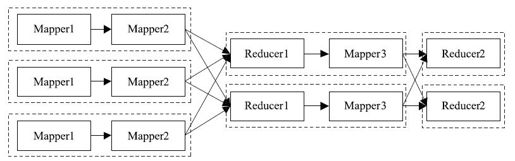
图 3-28 一个ChainMapper/ChainReducer不适用的场景
1.编程实例
这里以图3-27中的作业为例,给出ChainMapper/ChainReducer的基本使用方法,具体代码如下:
……
conf.setJobName("chain");
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
JobConf mapper1Conf=new JobConf(false);
JobConf mapper2Conf=new JobConf(false);
JobConf reduce1Conf=new JobConf(false);
JobConf mapper3Conf=new JobConf(false);
……
ChainMapper.addMapper(conf, Mapper1.class, LongWritable.class, Text.class, Text.class, Text.class, true, mapper1Conf);
ChainMapper.addMapper(conf, Mapper2.class, Text.class, Text.class, LongWritable.class, Text.class, false, mapper2Conf);
ChainReducer.setReducer(conf, Reducer.class, LongWritable.class, Text.class, Text.class, Text.class, true, reduce1Conf);
ChainReducer.addMapper(conf, Mapper3.class, Text.class, Text.class, LongWritable.class, Text.class, false, null);
JobClient.runJob(conf);
用户通过addMapper在Map/Reduce阶段添加多个Mapper。该函数带有8个输入参数,分别是作业的配置、Mapper类、Mapper的输入key类型、输入value类型、输出key类型、输出value类型、key/value是否按值传递和Mapper的配置。其中,第7个参数需要解释一下:Hadoop MapReduce有一个约定,函数OutputCollector.collect(key, value)执行期间不应改变key和value的值。这主要是因为函数Mapper.map()调用完OutputCollector.collect(key, value)之后,可能会再次使用key和value值,如果被改变,可能会造成潜在的错误。为了防止OutputCollector直接对key/value修改,ChainMapper允许用户指定key/value传递方式。如果用户确定key/value不会被修改,则可选用按引用传递,否则按值传递。需要注意的是,引用传递可避免对象拷贝,提高处理效率,但需要确保key/value不会被修改。
2.实现原理分析
ChainMapper/ChainReducer实现的关键技术点是修改Mapper和Reducer的输出流,将本来要写入文件的输出结果重定向到另外一个Mapper中。在3.3.4节中提到,结果的输出由OutputCollector管理,因而,ChainMapper/ChainReducer需要重新实现一个OutputCollector完成数据重定向功能。
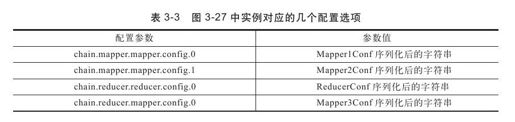
尽管链式作业在Map和Reduce阶段添加了多个Mapper,但仍然只是一个MapReduce作业,因而只能有一个与之对应的JobConf对象。然而,当用户调用addMapper添加Mapper时,可能会为新添加的每个Mapper指定一个特有的JobConf,为此,ChainMapper/ChainReducer将这些JobConf对象序列化后,统一保存到作业的JobConf中。图3-27中的实例可能产生如表3-3所示的几个配置选项。
当链式作业开始执行的时候,首先将各个Mapper的JobConf对象反序列化,并构造对应的Mapper和Reducer对象,添加到数据结构mappers(List<Mapper>类型)和reducer(Reducer类型)中。ChainMapper中实现的map()函数如下,它调用了第一个Mapper,是后续Mapper的“导火索”。
public void map(Object key, Object value, OutputCollector output,
Reporter reporter)throws IOException{
Mapper mapper=chain.getFirstMap();
if(mapper!=null){
mapper.map(key, value, chain.getMapperCollector(0,output, reporter),reporter);
}
}
chain.getMapperCollector返回一个OutputCollector实现——ChainOutputCollector,它的collect方法如下:
public void collect(K key, V value)throws IOException{
if(nextMapperIndex<mappers.size()){
//调用下一个Mapper
nextMapper.map(key, value,
new ChainOutputCollector(nextMapperIndex,
nextKeySerialization,
nextValueSerialization, output, reporter),
reporter);
}else{
//如果是最后一个Mapper,则直接调用真正的OutputCollector
output.collect(key, value);
}
