第4章 Hadoop RPC框架解析
网络通信模块是分布式系统中最底层的模块。它直接支撑了上层分布式环境下复杂的进程间通信(Inter-Process Communication, IPC)逻辑,是所有分布式系统的基础。远程过程调用(Remote Procedure Call, RPC)是一种常用的分布式网络通信协议。它允许运行于一台计算机的程序调用另一台计算机的子程序,同时将网络的通信细节隐藏起来,使得用户无须额外地为这个交互作用编程。由于RPC大大简化了分布式程序开发,因此备受欢迎。
作为一个分布式系统,Hadoop实现了自己的RPC通信协议,它是上层多个分布式子系统(如MapReduce, HDFS, HBase[1]等)公用的网络通信模块。本章首先从框架设计及实现等方面介绍了Hadoop RPC,接着介绍了该RPC框架在Hadoop MapReduce中的应用。
4.1 Hadoop RPC框架概述
RPC实际上是分布式计算中客户机/服务器(Client/Server)模型的一个应用实例。对于Hadoop RPC而言,它具有以下几个特点。
❑透明性:这是所有RPC框架的最根本特征,即当用户在一台计算机的程序调用另外一台计算机上的子程序时,用户自身不应感觉到其间涉及跨机器间的通信,而是感觉像是在执行一个本地调用。
❑高性能:Hadoop各个系统(如HDFS, MapReduce)均采用了Master/Slave结构。其中,Master实际上是一个RPC server,它负责处理集群中所有Slave发送的服务请求。为了保证Master的并发处理能力,RPC server应是一个高性能服务器,能够高效地处理来自多个Client的并发RPC请求。
❑可控性:JDK中已经自带了一个RPC框架——RMI(Remote Method Invocation,远程方法调用)。之所以不直接使用该框架,主要是因为考虑到RPC是Hadoop最底层、最核心的模块之一,保证其轻量级、高性能和可控性显得尤为重要,而RMI过于重量级且用户可控之处太少(如网络连接、超时和缓冲等均难以定制或者修改)[2]。
与其他RPC框架一样,Hadoop RPC主要分为四个部分,分别是序列化层、函数调用层、网络传输层和服务器端处理框架,具体实现机制如下:
❑序列化层:序列化层的主要作用是将结构化对象转为字节流以便于通过网络进行传输或写入持久存储。在RPC框架中,它主要用于将用户请求中的参数或者应答转化成字节流以便跨机器传输。第3章中已经提到,Hadoop自己实现了序列化框架,一个类只要实现Writable接口,即可支持对象序列化与反序列化。
❑函数调用层:函数调用层的主要功能是定位要调用的函数并执行该函数。HadoopRPC采用Java反射机制与动态代理实现了函数调用,具体参考4.2.1节。
❑网络传输层:网络传输层描述了Client与Server之间消息传输的方式。Hadoop RPC采用了基于TCP/IP的Socket机制,具体参考4.2.2节。
❑服务器端处理框架:服务器端处理框架可被抽象为网络I/O模型。它描述了客户端与服务器端间信息交互的方式。它的设计直接决定着服务器端的并发处理能力。常见的网络I/O模型有阻塞式I/O、非阻塞式I/O、事件驱动I/O等,而Hadoop RPC采用了基于Reactor设计模式的事件驱动I/O模型,具体参考4.2.3节。
Hadoop RPC总体架构如图4-1所示,自下而上可分为两层。第一层是一个基于Java NIO(New IO)实现的客户机/服务器(Client/Server)通信模型。其中,客户端将用户的调用方法及其参数封装成请求包后发送到服务器端。服务器端收到请求包后,经解包、调用函数、打包结果等一系列操作后,将结果返回给服务器端。为了增强Server端的扩展性和并发处理能力,Hadoop RPC采用了基于事件驱动的Reactor设计模式,在具体实现时,用到了JDK提供的各种功能包,主要包括java.nio(NIO)、java.lang.reflect(反射机制和动态代理)、java.net(网络编程库)等。第二层是供更上层程序直接调用的RPC接口,这些接口底层即为客户机/服务器通信模型。
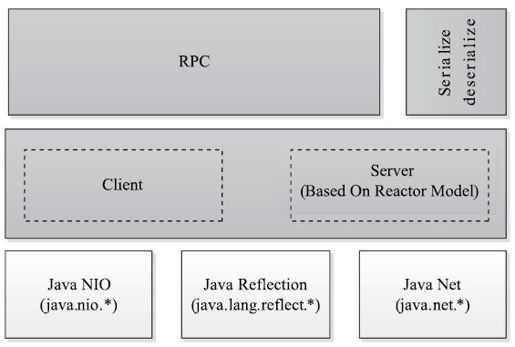
图 4-1 Hadoop RPC总体架构图
[1]HBase RPC在Hadoop RPC基础上做了部分改进。
[2]Doug Cutting在最初设计Hadoop时是这样描述Hadoop RPC设计动机的。
