4.3.2 Hadoop RPC基本框架
1.Hadoop RPC使用
在正式介绍Hadoop RPC基本框架之前,先介绍怎么样使用它。Hadoop RPC主要对外提供了两种接口。
❑public static VersionedProtocol getProxy/waitForProxy():构造一个客户端代理对象(该对象实现了某个协议),用于向服务器端发送RPC请求。
❑public static Server getServer():为某个协议(实际上是Java接口)实例构造一个服务器对象,用于处理客户端发送的请求。
通常而言,Hadoop RPC使用方法可分为以下几个步骤。
步骤1 定义RPC协议。RPC协议是客户端和服务器端之间的通信接口,它定义了服务器端对外提供的服务接口。如以下代码所示,我们定义了一个ClientProtocol通信接口,它声明了两个方法:echo()和add()。需要注意的是,Hadoop中所有自定义RPC接口都需要继承VersionedProtocol接口,它描述了协议的版本信息。
interface ClientProtocol extends org.apache.hadoop.ipc.VersionedProtocol{
//版本号。默认情况下,不同版本号的RPC Client和Server之间不能相互通信
public static final long versionID=1L;
String echo(String value)throws IOException;
int add(int v1,int v2)throws IOException;}
步骤2 实现RPC协议。Hadoop RPC协议通常是一个Java接口,用户需要实现该接口。如以下代码所示,对ClientProtocol接口进行简单的实现:
public static class ClientProtocolImpl implements ClientProtocol{
public long getProtocolVersion(String protocol, long clientVersion){
return ClientProtocol.versionID;
}
public String echo(String value)throws IOException{
return value;
}
public int add(int v1,int v2)throws IOException{
return v1+v2;
}
}
步骤3 构造并启动RPC Server。直接使用静态方法getServer()构造一个RPC Server,并调用函数start()启动该Server:
server=RPC.getServer(new ClientProtocolImpl(),serverHost, serverPort,
numHandlers, false, conf);
server.start();
其中,serverHost和serverPort分别表示服务器的host和监听端口号,而numHandlers表示服务器端处理请求的线程数目。到此为止,服务器处理监听状态,等待客户端请求到达。
步骤4 构造RPC Client,并发送RPC请求。使用静态方法getProxy()构造客户端代理对象,直接通过代理对象调用远程端的方法,具体如下所示:
proxy=(ClientProtocol)RPC.getProxy(
ClientProtocol.class, ClientProtocol.versionID, addr, conf);
int result=proxy.add(5,6);
String echoResult=proxy.echo("result");
经过以上四步,我们便利用Hadoop RPC搭建了一个非常高效的客户机/服务器网络模型。接下来,我们将深入Hadoop RPC内部,剖析它的设计原理及设计技巧。
Hadoop RPC主要由三个大类组成,分别是RPC、Client和Server,分别对应对外编程接口、客户端实现和服务器端实现。
2.ipc.RPC类分析
RPC类实际上是对底层客户机/服务器网络模型的封装,以便为程序员提供一套更方便简洁的编程接口。
如图4-9所示,RPC类自定义了一个内部类RPC.Server。它继承Server抽象类,并利用Java反射机制实现了call接口(Server抽象类中并未给出该接口的实现),即根据客户端请求中的调用方法名称和对应参数完成方法调用。RPC类包含一个ClientCache类型的成员变量,它根据用户提供的SocketFactory缓存Client对象,以达到重用Client对象的目的。
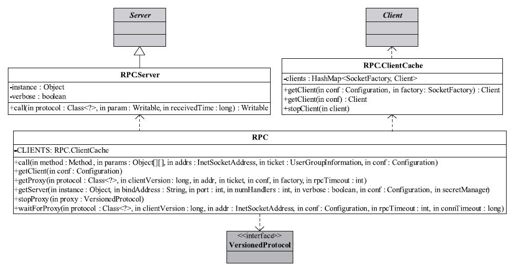
图 4-9 Hadoop RPC的主要类关系图
Hadoop RPC使用了Java动态代理完成对远程方法的调用。在4.2.1小节中,我们介绍了Java动态代理机制:用户只需实现java.lang.reflect.InvocationHandler接口,并按照自己的需求实现invoke方法即可完成动态代理类对象上的方法调用;我们还在代码中给出了一个本地动态代理实例。但对于Hadoop RPC,函数调用由客户端发出,并在服务器端执行并返回,因此不能像4.2.1节的本地动态代理实例代码一样直接在invoke方法中本地调用相关函数,它的做法是,在invoke方法中,将函数调用信息(函数名、函数参数列表等)打包成可序列化的Invocation对象,并通过网络发送给服务器端,服务器端收到该调用信息后,解析出函数名和函数参数列表等信息,利用Java反射机制完成函数调用,期间涉及的类关系如图4-10所示。
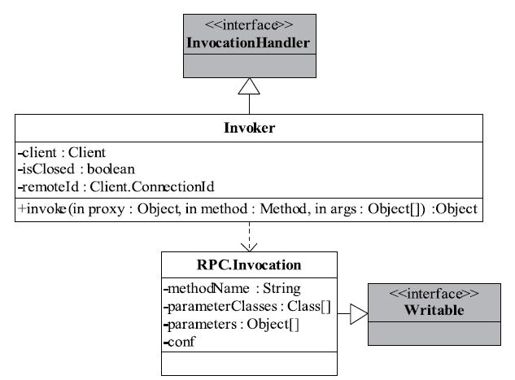
图 4-10 Hadoop RPC中服务器端动态代理实现类图
3.ipc.Client类分析
Client主要完成的功能是发送远程过程调用信息并接收执行结果。它涉及的类关系如图4-11所示。Client类对外提供了两种接口,一种用于执行单个远程调用。另外一种用于执行批量远程调用。它们的声明如下所示:
public Writable call(Writable param, ConnectionId remoteId)
throws InterruptedException, IOException;
public Writable[]call(Writable[]params, InetSocketAddress[]addresses,
Class<?>protocol, UserGroupInformation ticket, Configuration conf)
throws IOException, InterruptedException;
Client内部有两个重要的内部类,分别是Call和Connection。
❑Call类:该类封装了一个RPC请求,它包含五个成员变量,分别是唯一标识id、函数调用信息param、函数执行返回值value、出错或者异常信息error和执行完成标识符done。由于Hadoop RPC Server采用了异步方式处理客户端请求,这使得远程过程调用的发生顺序与结果返回顺序无直接关系,而Client端正是通过id识别不同的函数调用。当客户端向服务器端发送请求时,只需填充id和param两个变量,而剩下的三个变量:value, error和done,则由服务器端根据函数执行情况填充。
❑Connection类:Client与每个Server之间维护一个通信连接。该连接相关的基本信息及操作被封装到Connection类中。其中,基本信息主要包括:通信连接唯一标识(remoteId),与Server端通信的Socket(socket),网络输入数据流(in),网络输出数据流(out),保存RPC请求的哈希表(calls)等;操作则包括:
❑addCall——将一个Call对象添加到哈希表中;
❑sendParam——向服务器端发送RPC请求;
❑receiveResponse——从服务器端接收已经处理完成的RPC请求;
❑run——Connetion是一个线程类,它的run方法调用了receiveResponse方法,会一直等待接收RPC返回结果。
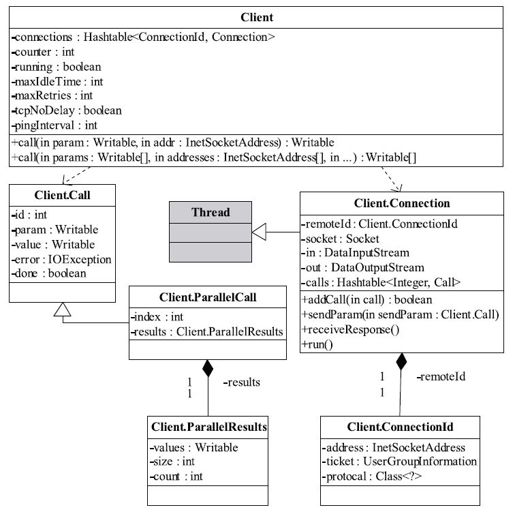
图 4-11 Client类图
当调用call函数执行某个远程方法时,Client端需要进行如图4-12所示的几个步骤:
步骤1 创建一个Connection对象,并将远程方法调用信息封装成Call对象,放到Connection对象中的哈希表calls中;
步骤2 调用Connetion类中的sendParam()方法将当前Call对象发送给Server端;
步骤3 Server端处理完RPC请求后,将结果通过网络返回给Client端,Client端通过receiveResponse()函数获取结果;
步骤4 Client端检查结果处理状态(成功还是失败),并将对应的Call对象从哈希表中删除。
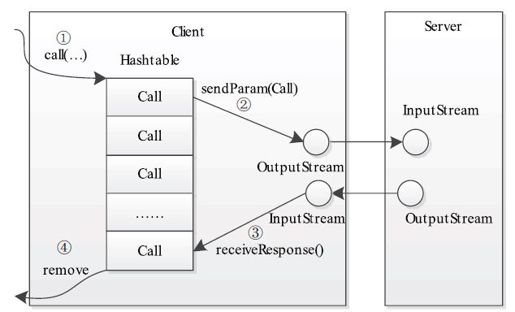
图 4-12 Hadoop RPC Client处理流程
4.ipc.Server类分析
Hadoop采用了Master/Slave结构。其中,Master是整个系统的单点,如NameNode或JobTracker,这是制约系统性能和可扩展性的最关键因素之一,而Master通过ipc.Server接收并处理所有Slave发送的请求,这就要求ipc.Server将高并发和可扩展性作为设计目标。为此,ipc.Server采用了很多具有提高并发处理能力的技术,主要包括线程池、事件驱动和Reactor设计模式等。这些技术均采用了JDK自带的库实现。这里重点分析它是如何利用Reactor设计模式提高整体性能的。
Reactor是并发编程中的一种基于事件驱动的设计模式。它具有以下两个特点:①通过派发/分离I/O操作事件提高系统的并发性能;②提供了粗粒度的并发控制,使用单线程实现,避免了复杂的同步处理。一个典型的Reactor实现原理图如图4-13所示。
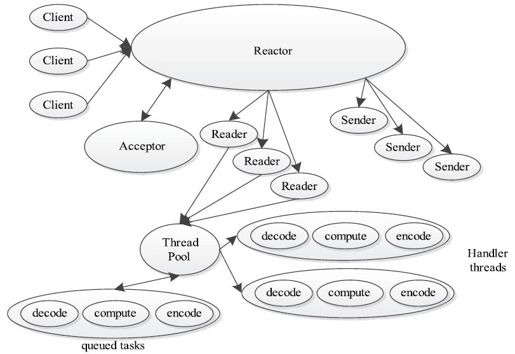
图 4-13 Reactor模式工作原理图
一个典型的Reactor模式中主要包括以下几个角色。
❑Reactor:IO事件的派发者。
❑Acceptor:接受来自Client的连接,建立与Client对应的Handler,并向Reactor注册此Handler。
❑Handler:与一个Client通信的实体,并按一定的过程实现业务的处理。Handler内部往往会有更进一步的层次划分,用来抽象诸如read, decode, compute, encode和send等的过程。在Reactor模式中,业务逻辑被分散的IO事件所打破,所以Handler需要有适当的机制在所需的信息还不全(读到一半)的时候保存上下文,并在下一次IO事件到来的时候(另一半可读了)能继续上次中断的处理。
❑Reader/Sender:为了加速处理速度,Reactor模式往往构建一个存放数据处理线程的线程池,这样,数据读出后,立即扔到线程池中等待后续处理即可。为此,Reactor模式一般分离Handler中的读和写两个过程,分别注册成单独的读事件和写事件,并由对应的Reader和Sender线程处理。
ipc.Server实际上实现了一个典型的Reactor设计模式,其整体架构与上述完全一致。读者一旦了解典型的Reactor架构,便可很容易地学习ipc.Server的设计思路及实现。接下来,我们分析ipc.Server的实现细节。
前面提到,ipc.Server的主要功能是接收来自客户端的RPC请求,经过调用相应的函数获取结果后,返回给对应的客户端。为此,ipc.Server被划分成三个阶段:接收请求,处理请求和返回结果。如图4-14所示,各阶段实现细节如下:
(1)接收请求
该阶段的主要任务是接收来自各个客户端的RPC请求,并将它们封装成固定的格式(Call类)放到一个共享队列(callQueue)中,以便进行后续处理。该阶段内部又分为两个子阶段:建立连接和接收请求,分别由两种线程完成:Listener和Reader。
整个Server只有一个Listener线程,统一负责监听来自客户端的连接请求。一旦有新的请求到达,它会采用轮询的方式从线程池中选择一个Reader线程进行处理。而Reader线程可同时存在多个,它们分别负责接收一部分客户端连接的RPC请求。至于每个Reader线程负责哪些客户端连接,完全由Listener决定。当前Listener只是采用了简单的轮询分配机制。
Listener和Reader线程内部各自包含一个Selector对象,分别用于监听SelectionKey.OP_ACCEPT和SelectionKey.OP_READ事件。对于Listener线程,主循环的实现体是监听是否有新的连接请求到达,并采用轮询策略选择一个Reader线程处理新连接;对于Reader线程,主循环的实现体是监听(它负责的那部分)客户端连接中是否有新的RPC请求到达,并将新的RPC请求封装成Call对象,放到共享队列callQueue中。
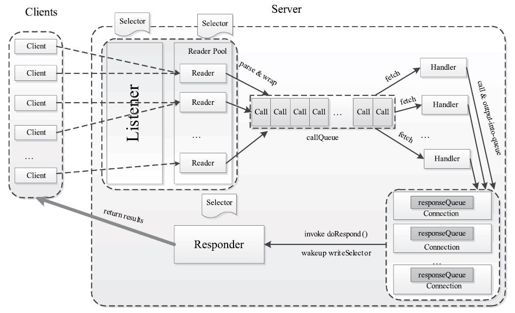
图 4-14 Hadoop RPC Server处理流程
(2)处理请求
该阶段的主要任务是从共享队列callQueue中获取Call对象,执行对应的函数调用,并将结果返回给客户端,这全部由Handler线程完成。
Server端可同时存在多个Handler线程。它们并行从共享队列中读取Call对象,经执行对应的函数调用后,将尝试着直接将结果返回给对应的客户端。但考虑到某些函数调用返回的结果很大或者网络速度过慢,可能难以将结果一次性发送到客户端,此时Handler将尝试着将后续发送任务交给Responder线程。
(3)返回结果
前面提到,每个Handler线程执行完函数调用后,会尝试着将执行结果返回给客户端,但对于特殊情况,比如函数调用返回的结果过大或者网络异常情况(网速过慢),会将发送任务交给Responder线程。
Server端仅存在一个Responder线程。它的内部包含一个Selector对象,用于监听SelectionKey.OP_WRITE事件。当Handler没能够将结果一次性发送到客户端时,会向该Selector对象注册SelectionKey.OP_WRITE事件,进而由Responder线程采用异步方式继续发送未发送完成的结果。
5.Hadoop RPC参数调优
Hadoop RPC对外提供了一些可配置参数,以便于用户根据业务需求和硬件环境对其进行调优,主要的配置参数如下。
❑Reader线程数目:由参数ipc.server.read.threadpool.size配置,默认是1。也就是说,默认情况下,一个RPC Server只包含一个Reader线程。
❑每个Handler线程对应的最大Call数目:由参数ipc.server.handler.queue.size指定,默认是100。也就是说,默认情况下,每个Handler线程对应的Call队列长度为100。比如,如果Handler数目为10,则整个Call队列(共享队列callQueue)最大长度为:100×10=1 000。
❑Handler线程数目:在Hadoop中,JobTracker和NameNode分别是MapReduce和HDFS两个子系统中的RPC Server,其对应的Handler数目分别由参数mapred.job.tracker.handler.count和dfs.namenode.service.handler.count指定,默认值均为10。当集群规模较大时,这两个参数值会大大影响系统性能。
❑客户端最大重试次数:在分布式环境下,因网络故障或者其他原因迫使客户端重试连接是很常见的,但尝试次数过多可能不利于对实时性要求较高的应用。客户端最大重试次数由参数ipc.client.connect.max.retries指定,默认值为10,也就是会连续尝试10次(每两次之间相隔1秒钟)。
