7.6 启动新任务
TaskTracker最重要的任务之一是启动JobTracker分配的新任务并周期性汇报它们的运行状态。一个任务的启动过程如图7-10所示,大致经历两个步骤:作业本地化和启动任务(包括任务本地化和运行任务)。
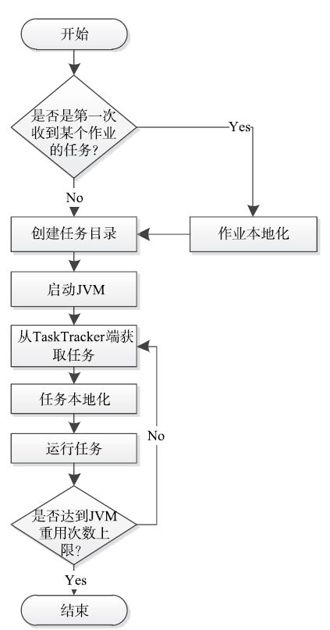
图 7-10 TaskTracker任务启动流程图
7.6.1 任务启动过程分析
1.作业本地化
本地化(localize)是指在TaskTracker上为作业和任务构造一个运行环境,包括创建作业和任务的工作目录,(从HDFS上)下载运行任务相关的文件,如程序jar包、字典文件等,设置环境变量等,可分为作业本地化和任务本地化。在同一个TaskTracker上,由作业的第一个任务完成该作业的本地化工作,后续任务只需进行任务本地化。
由于用户应用程序相关文件(比如jar包,字典文件等)可能很大,这使得任务花费较长时间从HDFS上下载这些数据,如果TaskTracker串行启动各个任务,势必会延长任务的启动时间。为了解决该问题,TaskTracker采用多线程启动任务,即为每个任务单独启动一个线程:
void startNewTask(final TaskInProgress tip){
Thread launchThread=new Thread(new Runnable(){
public void run(){
……
RunningJob rjob=localizeJob(tip);//作业本地化
tip.getTask().setJobFile(rjob.getLocalizedJobConf().toString());
launchTaskForJob(tip, new JobConf(rjob.getJobConf()),rjob);
……
}
}
}
为了防止同一个作业的多个任务同时进行作业本地化,TaskTracker需要对相关数据结构加锁。一种常见的加锁方法是:
RunningJob rjob;
……//对rjob赋值
synchronized(rjob){//获取rjob锁
initializeJob(rjob);/*作业本地化。如果作业文件很大,则该函数运行时间很长,这导致rjob锁
长时间不释放*/
}
在以上实现方案中,作业本地化过程会一直占用rjob锁,这导致很多其他需要该锁的线程或者函数不得不等待,如MapEventsFetcherThread线程、TaskTracker.getMap-CompletionEvents()函数等。
为了避免作业本地化过程中长时间占用rjob锁,TaskTracker为每个正在运行的作业维护两个变量:localizing和localized,分别表示正在进行作业本地化和已经完成作业本地化。通过对这两个变量的控制可避免作业本地化时对RunningJob对象加锁,且能够保证只有作业的第一个任务进行作业本地化:
synchronized(rjob){
if(!rjob.localized){//该作业尚未完成本地化工作
while(rjob.localizing){//另外一个任务正在进行作业本地化
rjob.wait();//等待作业本地化结束
}//释放rjob锁
if(!rjob.localized){//没有任务进行作业本地化
rjob.localizing=true;//让当前任务对该作业进行本地化
}
}
}
if(!rjob.localized){//运行到此,说明当前没有任务进行作业本地化
initializeJob(rjob);//进行作业本地化工作
}
在整个作业本地化过程中,<localizing, localized>两个变量值变化过程为:
<false, false>→<true, false>→<true, true>
作业的第一个任务负责为该作业本地化,具体步骤如下:
步骤1 将凭据文件jobToken和作业描述文件job.xml下载到TaskTracker私有文件目录中。
TaskTracker私有文件目录是${mapred.local.dir}/ttprivate,其中,不同用户的文件放到不同子目录下,比如用户$user提交的作业$jobid对应文件放在${mapred.local.dir}/ttprivate/taskTracker/$user/jobcache/$jobid/目录下。此外,在任务运行过程中,任务启动脚本taskjvm.sh(具体见下一小节)也存放在该目录下。
步骤2 将其他初始化工作交给TaskController.initializeJob函数处理。
TaskController类主要用于控制任务的初始化、终结和清理等工作,当前默认实现是DefaultTaskController。TaskController.initializeJob函数的主要工作是创建作业相关目录和文件,最终生成的目录结构如下。
❑${mapred. local.dir}/taskTracker/distcache/:TaskTracker上的public级别分布式缓存,该TaskTracker上所有用户的所有作业共享该缓存中的文件。
❑${mapred. local.dir}/taskTracker/$user/distcache/:TaskTracker上的private级别缓存,用户$user的所有作业共享该缓存中的文件。
❑${mapred. local.dir}/taskTracker/$user/jobcache/$jobid/:用户$user提交的作业$jobid对应的目录。
❑${mapred. local.dir}/taskTracker/$user/jobcache/$jobid/work/:作业共享目录,可作为任务的数据暂存目录或者共享目录,可通过JobConf.getJobLocalDir()函数获取。此外,它还在系统属性中,因此也可以通过System.getProperty("job.local.dir")获取。
❑${mapred. local.dir}/taskTracker/$user/jobcache/$jobid/jars/:存放作业jar文件和展开后的jar文件。程序相关的jar文件被统一命名成job.jar,并分发到各个节点上,且在任务运行之前,由Hadoop自动展开该文件。
❑${mapred. local.dir}/taskTracker/$user/jobcache/$jobid/job.xml:存放作业相关的配置属性。
❑$mapred. local.dir/taskTracker/$user/jobcache/$jobid/jobToken:作业凭据文件,用于保证作业运行安全。
❑$mapred. local.dir/taskTracker/$user/jobcache/$jobid/job-acls.xml:保存作业访问控制权限。
❑$hadoop. log.dir/userlogs/$jobid/:作业日志存放目录。
2.启动任务
为了避免不同任务之间相互干扰,TaskTracker为各个任务启动了独立的JVM。也就是说,JVM相当于包含一定资源量的容器,每个任务可在该容器使用其资源运行。这里先介绍JVM启动过程,然后介绍任务启动过程。
根据任务类型,TaskTracker会调用不同的TaskRunner启动任务。对于Map Task,会调用MapTaskRunner,而Reduce Task则调用ReduceTaskRunner,但任务启动最终均是由TaskRunner.run()方法完成的。
TaskRunner. run()方法首先准备启动任务需要的各种信息,包括启动命令、启动参数、环境变量、标准输出流、标准错误输出流等信息,然后交给JvmManager对象启动一个JVM。
JvmManager负责管理TaskTracker上所有正在使用的JVM,包括启动、停止、杀死JVM等。考虑到一般情况下Map Task和Reduce Task占用的资源量不同,JvmManager使用mapJvmManager和reduceJvmManager单独管理两种类型任务对应的JVM,且规定:
❑每个TaskTracker上同时启动的Map Task和Reduce Task数目不能超过Map slot和Reduce slot数目;
❑每个JVM只能同时运行一个任务;
❑每个JVM可重复使用以减少启动开销(重用次数可通过参数mapred.job.reuse.jvm.num.tasks指定),但某个JVM只限于同一个作业的同类型任务使用。这一点可从Jvm ID中看出,它是某个作业ID(将其ID标识字符串“job”变为“jvm”),任务类型和一个随机整型拼接而成的,比如jvm_201209031104_0010_m_482270223。
JVM启动过程如下:
步骤1 如果已启动JVM数目低于上限数目(Map slot或者Reduce slot数目),则直接启动JVM,否则进入步骤2。
步骤2 查找当前TaskTracker所有已经启动的JVM,找出满足以下条件的JVM:
❑当前状态为空闲;
❑复用次数未超过上限数目;
❑与将要启动的任务同属一个作业(通过Jvm ID可获取作业ID)。
如果找到这样的JVM,则可继续复用而无须启动新的JVM,否则进入步骤3。
步骤3 查找当前TaskTracker所有已经启动的JVM,如果满足以下两个条件之一,则直接将该JVM杀掉,并启动一个新的JVM。
❑复用次数已达到上限数目且与新任务同属一个作业;
❑当前处于空闲状态但与新任务不属于同一作业。
启动JVM是由JvmRunner线程完成的,它进一步调用了TaskController中的launchTask方法。在DefaultTaskController实现中,该方法首先在本地磁盘创建任务工作目录,接着将任务启动命令写到Shell脚本taskjvm.sh中,并直接使用以下命令运行该脚本以启动任务:
bash-c taskjvm.sh
其中,一个taskjvm.sh实例如下:
export JVM_PID=echo$$
export HADOOPCLIENT_OPTS="-Dhadoop.tasklog.taskid=attempt_201209010905_0002
m_000000_0-Dhadoop.tasklog.iscleanup=false-Dhadoop.tasklog.totalLogFileSize=0"
export SHELL="/bin/bash"
export HADOOP_WORK_DIR="/tmp/mapred/taskTracker/intuser/jobcache/
job_201209010905_0002/attempt_201209010905_0002_m_000000_0/work"
export HOME="/homes/"
export LOGNAME="dongxicheng"
export HADOOP_TOKEN_FILE_LOCATION="/tmp/mapred/taskTracker/intuser/jobcache/
job_201209010905_0002/jobToken"
export HADOOP_ROOT_LOGGER="INFO, TLA"
export LD_LIBRARY_PATH="/tmp/mapred/taskTracker/intuser/jobcache/
job_201209010905_0002/attempt_201209010905_0002_m_000000_0/work:/usr/lib/jvm/
java-1.6.0-openjdk-1.6.0.0.x86_64/jre/lib/amd64/server:/usr/lib/jvm/java-
1.6.0-openjdk-1.6.0.0.x86_64/jre/lib/amd64:/usr/lib/jvm/java-1.6.0-openjdk-
1.6.0.0.x86_64/jre/../lib/amd64"
export USER="dongxicheng"
exec setsid'/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.0.x86_64/jre/bin/java'……
'-Dhadoop.log.dir=/home/dongxicheng/hadoop-1.0.0/libexec/../logs'
'-Dhadoop.root.logger=INFO, TLA'
'-Dhadoop.tasklog.taskid=attempt_201209010905_0002_m_000000_0'
'-Dhadoop.tasklog.iscleanup=false''-Dhadoop.tasklog.totalLogFileSize=0'
'org.apache.hadoop.mapred.Child''127.0.0.1''47655''attempt201209010905_0002
m_000000_0''/home/
dongxicheng/hadoop-1.0.0/libexec/../logs/userlogs/job_201209010905_0002/
attempt_201209010905_0002_m_000000_0''400940185'</dev/null 1>>/home/
dongxicheng/hadoop-1.0.0/libexec/../logs/userlogs/job_201209010905_0002/
attempt_201209010905_0002_m_000000_0/stdout2>>/home/
dongxicheng/hadoop-1.0.0/libexec/../logs/userlogs/job_201209010905_0002/
attempt_201209010905_0002_m_000000_0/stderr
可以看到,最终是通过org.apache.hadoop.mapred.Child类运行任务的,即
org.apache.hadoop.mapred.Child<host><port><task-attempt-id><log-location><jvm-id>
上面代码中的五个输入参数分别表示TaskTracker的IP、端口号、Task Attempt ID、日志位置和JVM ID。
其中,org.apache.hadoop.mapred.Child类的核心代码框架如下:
public static void main(String[]args)throws Throwable{
//创建RPC Client,启动日志同步线程
……
while(true){//不断询问TaskTracker,以获取新任务
JvmTask myTask=umbilical.getTask(context);//获取新任务
if(myTask.shouldDie()){//JVM所属作业不存在或者被杀死
break;
}else{
if(myTask.getTask()==null){//暂时没有新任务
//等待一段时间继续询问TaskTracker
……
continue;
}
}
//有新任务,进行任务本地化
……
taskFinal.run(job, umbilical);//启动该任务
……
//如果JVM复用次数达到上限数目,则直接退出
if(numTasksToExecute>0&&++numTasksExecuted==numTasksToExecute){
break;
}
}
}
其中任务本地化涉及内容如下:
1)将任务相关的一些配置参数添加到作业配置JobConf中(如果参数名相同,则会覆盖),形成任务自己的配置JobConf,并采用轮询的方式选择一个目录存放对应的任务对象配置文件。也就是说,任务的JobConf是由作业的JobConf与任务特定参数组成的,其中,任务特定参数如表7-3所示。
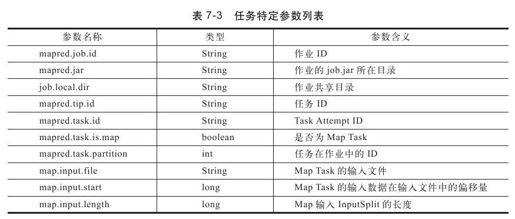
2)在工作目录中建立指向分布式缓存中所有数据文件的链接,以便能够直接使用这些文件。
最终,形成的任务目录结构如下。
❑${mapred. local.dir}/taskTracker/$user/jobcache/$jobid/$taskid:作业$jobid中的任务$taskid对应的目录。
〇${mapred.local.dir}/taskTracker/$user/jobcache/$jobid/$taskid/job.xml:任务本地化后产生的与该任务对应的配置文件。
〇${mapred.local.dir}/taskTracker/$user/jobcache/$jobid/$taskid/split.info:任务的InputSplit元数据信息,仅用于IsolationRunner调试。
〇${mapred.local.dir}/taskTracker/$user/jobcache/$jobid/$taskid/output:存放中间输出文件的目录,比如Map Task的中间输出结果。
〇${mapred.local.dir}/taskTracker/$user/jobcache/$jobid/$taskid/work:任务的工作目录。
〇${mapred.local.dir}/taskTracker/$user/jobcache/$jobid/$taskid/work/tmp:任务的临时目录。用户可通过参数mapred.child.tmp设置Map Task和Reduce Task的临时目录,默认值是./tmp。如果该值不是绝对路径,则任务是相对于工作目录的相对路径。当启动JVM时,会将-Djava.io.tmpdir=’the tmp dir’作为启动参数。
❑$hadoop. log.dir/userlogs/$jobid/$taskid:作业$jobid中任务$taskid的日志目录。该目录下的主要文件或子目录如下。
〇$hadoop.log.dir/userlogs/$jobid/$taskid/stdout:应用程序打印的标准输出数据,比如Java应用程序中使用System.out.print()函数打印的输出数据。
〇$hadoop.log.dir/userlogs/$jobid/$taskid/stderr:应用程序打印的标准错误输出数据,比如Java应用程序中使用System.err.print()函数打印的输出数据。
〇$hadoop.log.dir/userlogs/$jobid/$taskid/syslog:应用程序和MapReduce框架打印的系统日志,比如应用程序中使用LOG(INFO)打印的日志。
〇$hadoop.log.dir/userlogs/$jobid/$taskid/profile.out:profiling日志。当用户设置配置选项mapred.task.profile=true时,TaskTracker会启用任务的profiling功能,这会根据用户要求采集任务的运行时信息并保存到profile.out文件中,以方便用户对应用程序调优。
〇$hadoop.log.dir/userlogs/$jobid/$taskid/debugout:Debug脚本的标准输出。用户可通过参数mapred.map.task.debug.script和mapred.reduce.task.debug.script指定任务失败时需运行的调试脚本。
Debug脚本的标准输出举例如下:
步骤1 编写应用程序。
为了简化问题,我们采用Hadoop Streaming编写应用程序。为了能够让任务运行失败,我们在Map Task处理第5行数据记录时,打印一个空指针,对应的C++代码如下:
include<string>
include<iostream>
using namespace std;
int main(){
string key;
int errorno=1;
while(cin>>key){
cout<<key<<"\t"<<"1"<<endl;
if(errorno++==5){
int*p=NULL;
cout<<*p<<endl;//当处理到第5行记录时,让Map Task运行失败
}
}
return 0;
}
编译以上程序生成可执行程序Mapper,我们将该可执行文件作为MapReduce程序的Mapper。
步骤2 编写作业提交脚本。
编写应用程序提交脚本,内容如下:
bin/hadoop jar contrib/streaming/hadoop-streaming-1.0.0.jar\
-mapper Mapper\
-reducer NONE\
-input/home/dongxicheng/input\
-output/home/dongxicheng/output\
-file Mapper\
-file debug_map.sh\
-mapdebug./debug_map.sh
其中,Map Task调试脚本debug_map.sh[1]内容如下:
core=find.-name'core*';
gdb-quiet./Mapper-c$core-ex'info threads'-ex'backtrace'-ex'quit'
步骤3 准备好输入数据后,提交作业,可在$hadoop.log.dir/userlogs/$jobid/$taskid/debugout中看到调试脚本输出结果。
$hadoop. log.dir/userlogs/$jobid/$taskid/log.index:日志索引文件。当JVM允许复用时,所有复用同一个JVM的任务会将日志保存在第一个任务的日志文件中,因此,需要一个日志索引文件保存日志实际存放位置以及每个任务对应的标准输出日志、标准错误输出日志和系统日志在文件stdout、stderr和syslog中的偏移量,具体格式如下:
LOG_DIR:<the dir where the task logs are really stored>
stdout:<start-offset in the stdout file><length>
stderr:<start-offset in the stderr file><length>
syslog:<start-offset in the syslog file><length>
[1]由于调试信息是从core文件中获取的,因此提交作业前应修改Linux相关配置以确保能够生成core文件。http://lxc.sourceforge.net/
