8.5.2 系统优化
本小节主要讨论Hadoop的性能优化方向,但并不涉及对其架构进行大的调整或者改变其应用场景。
在Apache Hadoop中,Map/Reduce Task实现存在诸多不足之处,比如强制使用基于排序的聚集策略,Shuffle机制实现过于低效等。为此,下一代MapReduce提出了很多优化和改进方案,主要体现在以下几个方面[1]。
1.避免排序[2]
Hadoop采用了基于排序的数据聚集策略,而该策略是不可以定制的。也就是说,用户不可以使用其他数据聚集算法(如Hash聚集),也不可以跳过该阶段。而在实际应用中,很多应用可能不需要对数据进行排序,比如Hash join,或者基于排序的方法非常低效,比如SQL中的“limit-k”。为此,HDH版本[3]提出将排序变成可选环节,这可带来以下几个方面的改进:
❑在Map Collect阶段,不再需要同时比较partition和key,只需比较partition,并可使用更快的计数排序(O(lgN))代替快速排序(O(NlgN))。
❑在Map Combine阶段,不再需要进行归并排序,只需按照字节合并数据块即可。
❑去掉排序后,Shuffle和Reduce可同时进行,即Reduce阶段可提前运行,这就消除了Reduce Task的屏障(所有数据拷贝完成后才能执行reduce()函数)。
2.Shuffle阶段内部优化
(1)Map端——用Netty代替Jetty
1.0.0版本中,TaskTracker采用了Jetty服务器处理来自各个Reduce Task的数据读取请求。由于Jetty采用了非常简单的网络模型,因此性能比较低。在Apache Hadoop 2.0.0版本中,Hadoop改用Netty,它是另一种开源的客户/服务器端编程框架。由于它内部采用了Java NIO技术,相比Jetty更加高效,且Netty社区更加活跃,其稳定性比Jetty好。
(2)Reduce端——批拷贝
1.0.0版本中,在Shuffle过程中,Reduce Task会为每个数据分片建立一个专门的HTTP连接(One-connection-per-map),即使多个分片同时出现在一个TaskTracker上,也是如此。为了提高数据拷贝效率,Apache Hadoop 2.0.0尝试采用批拷贝技术:不再为每个Map Task建立一个HTTP连接,而是为同一个TaskTracker上的多个Map Task建立一个HTTP连接,进而能够一次读取多个数据分片,具体如图8-25所示。
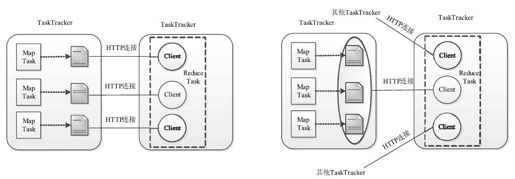
图 8-25 One-connection-per-map与批拷贝模型对比
3.将Shuffle阶段从Reduce Task中拆分出来
前面提到,对于一个作业而言,当一定比例(默认是5%)的Map Task运行完成后,Reduce Task才开始被调度,且仅当所有Map Task运行完成后,Reduce Task才可能运行完成。在所有Map Task运行完成之前,已经启动的Reduce Task将始终处于Shuffle阶段,此时它们不断从已经完成的Map Task上远程拷贝中间处理结果,由于随着时间推移,不断会有新的Map Task运行完成,因此Reduce Task会一直处于“等待—拷贝—等待—拷贝……”的状态。待所有Map Task运行完成后,Reduce Task才可能将结果全部拷贝过来,这时候才能够进一步调用用户编写的reduce()函数处理数据。从以上Reduce Task内部运行流程分析可知,Shuffle阶段会带来两个问题:slot Hoarding和资源利用率低下。
(1)Slot Hoarding现象
Slot Hoarding是一种资源囤积现象,具体表现是:对于任意一个MapReduce作业而言,在所有Map Task运行完成之前,已经启动的Reduce Task将一直占用着slot不释放。Slot Hoarding可能会导致一些作业产生饥饿现象。下面给出一个例子进行说明。
【实例】如图8-26所示,整个集群中有三个作业,分别是job1、job2和job3,其中,job1的Map Task数目非常多,而其他两个作业的Map Task相对较少。在t0时刻,job1和job2的Reduce Task开始被调度;在t3时刻,job2的所有Map Task运行完成,不久之后(t3'时刻),job2的第一批Reduce Task运行完成;在t4'时刻,job2所有Reduce Task运行完成;在t4时刻,job3的Map Task开始运行并在t7时刻运行完成,但由于此时所有Reduce slot均被job1占用着,因此,除非job1的所有Map Task运行完成,否则job3的Reduce Task永远不可能得到调度。

图 8-26 多个作业产生Slot Hoarding现象
(2)资源利用率低下
从资源利用率角度看,为了保证较高的系统资源利用率,所有Task都应充分使用一个slot所隐含的资源,包括内存、CPU、I/O等资源。然而,对单个Reduce Task而言,在整个运行过程中,它的资源利用率很不均衡,总体上看,刚开始它主要使用I/O资源(Shuffle阶段),之后主要使用CPU资源(Reduce阶段)。如图8-27所示,t4时刻之前,所有已经启动的Reduce Task处于Shuffle阶段,此时主要使用网络I/O和磁盘I/O资源,而在t4时刻之后,所有Map Task运行完成,则第一批Reduce Task逐渐开始进入Reduce阶段,此时主要消耗CPU资源。由此可见,Reduce Task运行过程中使用的资源依次以I/O、CPU为主,并没有重叠使用这两种资源,这使得系统整体资源利用率低下。

图 8-27 单个作业的Reduce Task资源利用率分析
经过以上分析可知,I/O密集型的数据拷贝(Shuffle阶段)和CPU密集型的数据计算(Reduce阶段)紧耦合在一起是导致“Slot Hoarding”现象和系统资源利用率低下的主要原因。为了解决该问题,一种可行的解决方案是将Shuffle阶段从Reduce Task中分离出来,当前主要有以下两种具体的实现方案。
❑Copy-Compute Splitting:这是Berkeley的一篇论文[4]提出的解决方案。该方案从逻辑上将Reduce Task拆分成“Copy Task”和“Compute Task”,其中,Copy Task用于数据拷贝,而Compute Task用于数据计算(调用用户编写的reduce()函数处理数据)。当一个Copy Task运行完成后,它会触发一个Compute Task进行数据计算,同时另外一个Copy Task将被启动拷贝另外的数据,从而实现I/O和CPU资源重叠使用。
❑将Shuffle阶段变为独立的服务:将Shuffle阶段从Reduce Task处理逻辑中出来变成为一个独立的服务,不再让其占用Reduce slot,这样也可达到I/O和CPU资源重叠使用的目的。“百度”曾采用了这一方案[5]。
4.用C++改写Map/Reduce Task
利用C++实现Map/Reduce Task可借助C++语言独特的优势提高输出性能。当前比较典型的实现是NativeTask[6]。NativeTask是一个C++实现的高性能MapReduce执行单元,它专注于数据处理本身。在MapReduce的环境下,它仅替换Task模块功能。也就是说,NativeTask并不关心资源管理、作业调度和容错等,这些功能仍旧由原有的Hadoop相应模块完成,而实际的数据处理则改由这个高性能处理引擎完成。
与Hadoop MapReduce相比,NativeTask获得了不错的性能提升,主要包括更好的排序实现、关键路径避免序列化、避免复杂抽象、更好地利用压缩等。
[1]本节主要讨论Hadoop的性能优化方法,这些方法不会对其进行大的调整,比如改变其架构或者应用场景(离线改为在线)。
[2]https://issues. apache.org/jira/browse/MAPREDUCE-4039
[3]https://github. com/hanborq/hadoop
[4]M. Zaharia, D.Borthakur, J.S.Sarma, K.Elmeleegy, S.Shenker, and I.Stoica,“Job scheduling for multi-user mapreduce clusters,”EECS Department, University of California, Berkeley, Tech.Rep.,Apr 2009.
[5]连林江:“百度分布式计算技术发展”,PPT,2012.07.08。
[6]https://github. com/decster/nativetask
