9.3.2 作业级别参数调优
1.规划合理的任务数目
一个作业的任务数目对作业运行时间有重要的影响。如果一个作业的任务数目过多(这意味着每个任务处理数据很少,执行时间很短),则任务启动时间所占比例将会大大增加;反之,如果一个作业的任务数目过少(这意味着每个任务处理数据很多,执行时间很长),则可能会产生过多的溢写数据影响任务执行性能,且任务失败后重新计算代价过大。在Hadoop中,每个Map Task处理一个Input Split。Input Split的划分方式是由用户自定义的InputFormat决定的,默认情况下,由以下三个配置参数决定。
❑mapred. min.split.size:Input Split的最小值(在mapred-site.xml中配置)。
❑mapred. max.split.size:Input Split的最大值(在mapred-site.xml中配置)。
❑dfs. block.size:HDFS中一个block大小(在hdfs-site.xml中配置)。
Map Task数目的具体算法可参考3.2.2小节。
对于Reduce Task而言,每个作业的Reduce Task数目通常由用户决定。用户可根据估算的Map Task输出数据量设置Reduce Task数目,以防止每个Reduce Task处理的数据量过大造成大量写磁盘操作。
2.增加输入文件副本数
如果一个作业并行执行的任务数量非常多,那么这些任务共同的输入文件可能成为瓶颈。为防止多个任务并行读取一个文件内容造成瓶颈,用户可根据需要增加输入文件的副本数目。用户可通过在客户端配置文件hdfs-site.xml中增加以下配置选项修改文件副本数,比如将客户端上传的所有数据副本数设置为5[1]:
<property>
<name>dfs.replication</name>
<value>5</value>
</property>
3.启用推测执行机制
推测执行是Hadoop对“拖后腿”任务的一种优化机制。当一个作业的某些任务运行速度明显慢于同作业的其他任务时,Hadoop会在另一个节点上为“慢任务”启动一个备份任务,这样,两个任务同时处理一份数据,而Hadoop最终会将优先完成的那个任务的结果作为最终结果,并将另外一个任务杀掉。
用户可通过表9-10所示的参数设置是否为Map Task和Reduce Task启用推测执行机制。

不同Hadoop版本,采用的推测执行算法不同,具体可参考6.6节。
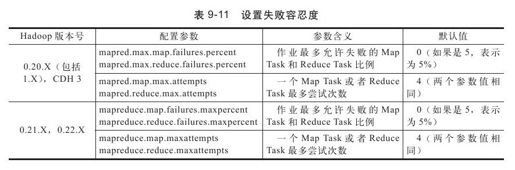
4.设置失败容忍度
Hadoop允许设置作业级别和任务级别的失败容忍度。作业级别的失败容忍是指Hadoop允许每个作业有一定比例的任务运行失败,这部分任务对应的输入数据将被忽略(这些数据不会有产出);任务级别的失败容忍是指Hadoop允许任务运行失败后再次在另外节点上尝试运行,如果一个任务经过若干次尝试运行后仍然运行失败,那么Hadoop才会最终认为该任务运行失败。
用户应根据应用程序的特点设置合理的失败容忍度,以尽快让作业运行完成和避免没必要的资源浪费,具体设置如表9-11所示。
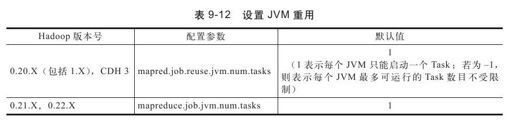
5.适当打开JVM重用功能
为了实现任务隔离,Hadoop将每个任务放到一个单独的JVM中执行,而对于执行时间较短的任务,JVM启动和关闭将占用很大比例的时间,为此,用户可启用JVM重用功能,这样,一个JVM可连续启动多个同类型任务,具体可参考7.6.1节。设置JVM重用的方法如表9-12所示。
6.设置任务超时时间
在一些特殊情况下,一个任务可能因为某种原因(比如程序Bug, Hadoop本身的Bug等)阻塞了,这会拖慢整个作业的执行进度,甚至可能导致作业无法运行结束。针对这种情况,Hadoop增加了任务超时机制。如果一个任务在一定时间间隔内没有汇报进度,则TaskTracker会主动将其杀死,从而在另外一个节点上重新启动执行。
用户可根据实际需要配置任务超时时间,配置方法如表9-13所示。

7.合理使用DistributedCache
当用户的应用程序需要一个外部文件(比如字典、配置文件等)时,通常需要使用DistributedCache将文件分发到各个节点上。一般情况下,得到外部文件有两种方法:一种是外部文件与应用程序jar包一起放到客户端,当提交作业时由客户端上传到HDFS的一个目录下,然后通过DistributedCache分发到各个节点上;另外一种方法是事先将外部文件直接放到HDFS上。从效率上讲,第二种方法比第一种更高效。第二种方式不仅节省了客户端上传文件的时间,还隐含着告诉DistributedCache:“请将文件下载到各节点的public级别(而不是private级别)共享目录中”,这样,后续所有的作业可重用已经下载好的文件,不必重复下载,即“一次下载,终生受益”,具体参考5.4节。
8.合理控制Reduce Task的启动时机
在MapReduce计算模型中,由于Reduce Task依赖于Map Task的执行结果,因此,从运算逻辑上讲,Reduce Task应晚于Map Task启动。在Hadoop中,合理控制Reduce Task启动时机不仅可以加快作业运行速度,而且可提高系统资源利用率。如果Reduce Task启动过早,则可能由于Reduce Task长时间占用Reduce slot资源造成“slot Hoarding”现象(具体可参考8.5.2节),从而降低资源利用率;反之,如果Reduce Task启动过晚,则会导致Reduce Task获取资源延迟,增加了作业运行时间。Hadoop配置Reduce Task启动时机的参数如表9-14所示。

9.跳过坏记录
Hadoop是用于处理海量数据的,对于大部分数据密集型应用而言,丢弃一条或者几条数据对最终结果的影响并不大,正因为如此,Hadoop为用户提供了跳过坏记录的功能。当一条或者几条坏数据记录导致任务运行失败时,Hadoop可自动识别并跳过这些坏记录,具体配置方法可参考6.5.4节。
10.提高作业优先级
所有Hadoop作业调度器进行任务调度时均会考虑作业优先级这一因素。一个作业的优先级越高,它能够获取的资源(指slot数目)也越多。需要注意的是,通常而言,在生产环境中,管理员已经按照作业重要程度对作业进行了分级,不同重要程度的作业允许配置的优先级不同,用户不可以擅自进行调整。Hadoop提供了5种作业优先级,分别是VERY_HIGH、HIGH、NORMAL、LOW和VERY_LOW。用户可在允许的范围内调整作业优先级以获取更多资源,可配置的参数如表9-15所示。

[1]为了防止该参数对所有文件生效,可创建一个专门的配置文件仅供有需求的数据使用。另外,该参数只对参数修改之后上传的文件有效,而已经上传的文件副本数不会改变。
