12.5.3 MapReduce与Mesos结合
由于Hadoop MapReduce的JobTracker和TaskTracker与Mesos模型中的Framework-scheduler和Executor在设计上是完全对应的,因此,只需修改少量代码便可让MapReduce运行于Mesos之上。
为了让Mesos支持MapReduce,需为其编写Scheduler和Executor两个组件。它们的作用如下:
(1)Scheduler
Mesos利用了Hadoop调度器可插拔的特性,重新实现了一个可接入Mesos的调度器MeosScheduler,以实现框架注册、资源分配等功能。
(2)Executor
Mesos为Hadoop实现了一个Executor——FrameworkExecutor。通过该Executor, Mesos可控制TaskTracker的启动或停止。比如,如果一定时间内没有任务运行,Mesos会关闭某些节点上的TaskTracker。
为了使Hadoop能运行于Mesos之上,JobTracker启动时通过调度器向Mesos注册,这之后,资源分配过程如图12-16所示,大致分为以下几个步骤:
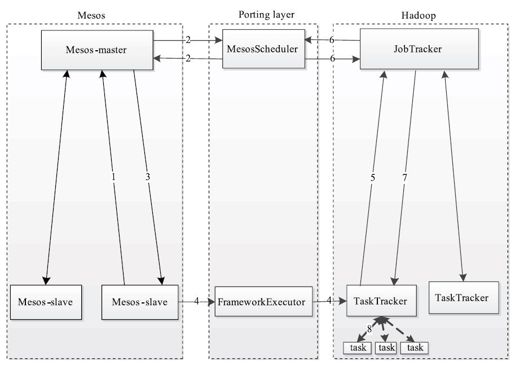
图 12-16 Hadoop在Mesos上工作流程
步骤1 Mesos-slave向Mesos-master汇报自己的资源使用情况,当前支持的资源类型包括CPU和内存两种。
步骤2 如果Mesos-slave上有空闲资源,Mesos-master会按照一定的策略将资源分配给当前向其注册的框架。如果分配给Hadoop,则告诉其调度器,它会按照一定的策略选出若干Hadoop任务并暂时缓存起来(稍后对应的TaskTracker通过心跳领取这些任务,见步骤5),并返回一系列Mesos-task列表(该任务的作用仅是在Hadoop任务正式启动之前为它准备资源,并不用于真正的计算),其中每个Mesos-task会对应一个Hadoop任务。
步骤3 Mesos-master将Mesos-task列表发送给对应的Mesos-slave。
步骤4 Mesos-slave收到一个Mesos-task后,检查它是否是收到的第一个来自Hadoop框架的任务,如果是,则通过Executor为其启动TaskTracker。
步骤5 与正常的Hadoop集群一样,TaskTracker向JobTracker汇报心跳,以领取新的计算任务(即步骤2中缓存起来的任务)。
步骤6 JobTracker收到来自TaskTracker的心跳后,通过调度器为其分配任务。需要注意的是,此时调度器分配多少任务并不取决于该TaskTracker上有多少空闲的slot,而是取决于Mesos为其分配的资源量(在步骤2中分配的资源量)。
步骤7 JobTracker将新分配的任务返回给对应的TaskTracker。
步骤8 TaskTracker收到新任务后,启动这些任务。需要注意的是,这些任务执行过程中的状态更新不仅会告诉TaskTracker,也会通过Executor汇报给Mesos。
