破茧:数据挖掘之智能生命的产生
每天早上一醒来,我就要问自己:怎么才能让数据流动得更好、管理得更好、分析得更好?07
——罗林·福特,沃尔玛首席信息官
数据仓库、联机分析技术的发展和成熟,为商务智能奠定了框架,但真正给商务智能赋予“智能”生命的是它的下一个产业链:数据挖掘。
一开始,数据挖掘曾一度被称为“基于数据库的知识发现”(Knowledge discovery in database)。随着数据仓库的产生,“数据挖掘”的叫法开始被广泛接受。也正是因为有了数据仓库的依托,数据挖掘如虎添翼,如“巧妇”走进了“米仓”,在实业界不断创造点“数”成金的故事。其中,最为经典的例子当属啤酒和尿布。
这是一个关于零售帝国沃尔玛的故事。
沃尔玛,是全世界最大的零售商,拥有8400多家分店、200多万雇员;它的人数,和美国联邦政府的雇员等量齐观;它的收入,2010年突破了4000亿美元,超过了很多国家的GDP总值。
沃尔玛拥有世界上数一数二的数据仓库,是最早应用数据挖掘技术的企业之一,也是数据挖掘技术的集大成者。在一次例行的数据分析之后,研究人员突然发现:跟尿布一起搭配购买最多的商品竟是啤酒!
数据挖掘(Data Mining)
数据挖掘是指通过特定的计算机算法对大量的数据进行自动分析,从而揭示数据之间隐藏的关系、模式和趋势,为决策者提供新的知识。
之所以称之为“挖掘”,是比喻在海量数据中寻找知识,就像开矿掘金一样困难。
尿布和啤酒,听起来风马牛不相及,但这是对历史数据进行挖掘的结果,反映的是数据层面的规律。
这种关系令人费解,这是一个真正的规律吗?
经过跟踪调查,研究人员终于发现事出有因:一些年轻的爸爸经常要到超市去购买婴儿尿布,有30%到40%的新爸爸会顺便买点啤酒犒劳自己。沃尔玛随后对啤酒和尿布进行了捆绑销售,不出意料,销售量双双增加。
沃尔玛还有很多利用数据挖掘扩大销售的故事。2004年,分析人员发现,每次飓风来临,一种袋装小食品“Pop-Tarts”的销售量都会明显上升。手电筒、电池、水,这些商品的销量会随着飓风的到来而上升,很容易理解,但Pop-Tarts的上升是不是必然的呢?
研究人员后来发现,这也是一个有用的规律:Pop-Tarts的销量上升,一是因为美国人喜欢甜食,二是因为它在停电时吃起来非常方便。此后,飓风来袭之前,沃尔玛也会提高Pop-Tarts的仓储量,以防脱销,并把它和水捆绑起来销售。
如果没有数据挖掘,Pop-Tarts和飓风的微妙关系就难以被发现。
1989年,可谓数据挖掘技术兴起的元年。
这一年,图灵奖的主办单位计算机协会(ACM)下属的知识发现和数据挖掘小组(SIGKDD)举办了第一届数据挖掘的学术年会,出版了专门期刊。此后,数据挖掘一直被热捧,其发展如火如荼,甚至成为一门独立的课目走进了大学课堂;在美国的不少大学,还先后设立了专门的数据挖掘硕士学位。
也正是1989年,高德纳咨询公司的德斯纳(Howard Dresner)在商业界为“商务智能”给出了一个正式的定义:
“商务智能(Business Intelligence),指的是一系列以事实为支持、辅助商业决策的技术和方法。”
这个定义,强调了商务智能是一系列技术的集合,获得了业界的广泛认同。
商务智能的概念在1989年完全破茧而出,并不是历史的巧合,而是因为数据挖掘这种新技术的出现,使商务智能真正具备了“智能”的内涵,也标志着商务智能完整产业链的形成。
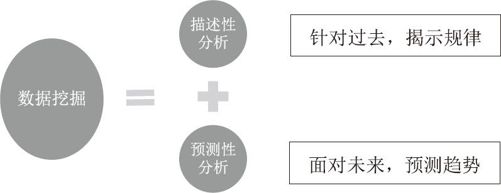
如果说联机分析是对数据的一种透视性的探测,数据挖掘则是对数据进行挖山凿矿式的开采。它的主要目的,一是要发现潜藏在数据表面之下的历史规律,二是对未来进行预测,前者称为描述性分析,后者称为预测性分析。沃尔玛发现的啤酒和尿布的销售关联性就是一种典型的描述性分析;考察所有历史数据,以特定的算法对下个月啤酒的销售量进行估测以确定进货量,则是一种预测性分析。
数据挖掘把数据分析的范围从“已知”扩大到了“未知”,从“过去”推向了“将来”,是商务智能真正的生命力和“灵魂”所在。它的发展和成熟,最终推动了商务智能在各行各业的广泛应用。
数据挖掘的两个侧重点
通过十多年的发展,数据挖掘的范围正在不断扩大。传统的数据挖掘是指在结构化的数据当中发现潜在的关系和规律,但随着商业竞争的白热化,更加高端的数据挖掘也开始初现端倪。例如,通过网络留言挖掘顾客的意见。顾客在博客、论坛、社交网站和微博上用文字记录的消费体验,对商品和服务发表的看法和评价,是一种非结构化的数据。如何把散布在网络上的这些资源整合起来,并从中自动挖掘有价值的信息和知识,正是当前数据挖掘面临的最大挑战之一。数据仓库之父比尔·恩门近年来就在这个领域多有建树。
结构化数据和非结构化数据
按结构,数据可以划分为两类:结构化数据和非结构化数据。
结构化数据是指存储在数据库当中、有统一结构和格式的数据,这种数据,比较容易分析和处理。非结构化数据是指无法用数字或统一的结构来表示的信息,包括各种文档、图像、音频和视频等,这种数据,没有统一的大小和格式,给分析和挖掘带来了更大的挑战。
从结构化数据到非结构化数据的推进,也代表着可供挖掘的数据在大幅增加。
