6.4 核密度图
在上节中,你看到了直方图上叠加的核密度图。用术语来说,核密度估计是用于估计随机变量概率密度函数的一种非参数方法。虽然其数学细节已经超出了本书的范畴,但从总体上讲,核密度图不失为一种用来观察连续型变量分布的有效方法。绘制密度图的方法(不叠加到另一幅图上方)为:
- Plot(density(x))
其中的x是一个数值型向量。由于plot()函数会创建一幅新的图形,所以要向一幅已经存在的图形上叠加一条密度曲线,可以使用lines()函数(如代码清单6-6所示)。
代码清单6-7给出了两幅核密度图示例,结果如图6-9所示。
代码清单6-7 核密度图
par(mfrow=c(2,1))d <- density(mtcars$mpg)plot(d)d <- density(mtcars$mpg)plot(d, main="Kernel Density of Miles Per Gallon")polygon(d, col="red", border="blue")rug(mtcars$mpg, col="brown")
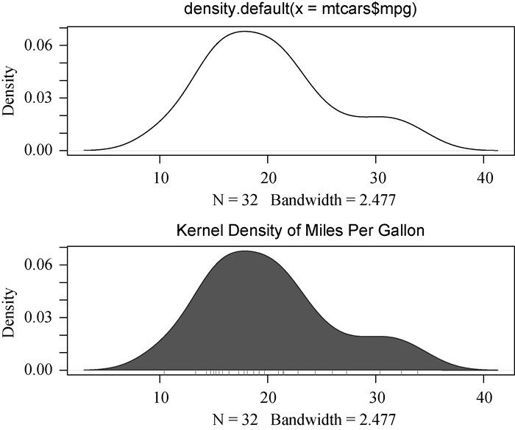
图6-9 核密度图
在第一幅图中,你看到的是完全使用默认设置创建的最简图形。在第二幅图中,你添加了一个标题,将曲线修改为蓝色,使用实心红色填充了曲线下方的区域,并添加了棕色的轴须图。polygon()函数根据顶点的x和y坐标(本例中由density()函数提供)绘制了多边形。
核密度图可用于比较组间差异。可能是由于普遍缺乏方便好用的软件,这种方法其实完全没有被充分利用。幸运的是,sm包漂亮地填补了这一缺口。
使用sm包中的sm.density.compare()函数可向图形叠加两组或更多的核密度图。使用格式为:
sm.density.compare(x, factor)
其中的x是一个数值型向量,factor是一个分组变量。请在第一次使用sm包之前先安装它。代码清单6-8中提供了一个示例,它比较了拥有4个、6个或8个汽缸车型的每加仑汽油行驶英里数。
代码清单6-8 可比较的核密度图
par(lwd=2) # ❶ 双倍线条宽度library(sm)attach(mtcars)cyl.f <- factor(cyl, levels= c(4,6,8), # ❷ 创建分组因子labels = c("4 cylinder", "6 cylinder","8 cylinder"))sm.density.compare(mpg, cyl, xlab="Miles Per Gallon") # ❸ 绘制密度图title(main="MPG Distribution by Car Cylinders")colfill<-c(2:(1+length(levels(cyl.f)))) # ❹ 通过鼠标单击添加图例legend(locator(1), levels(cyl.f), fill=colfill)detach(mtcars)
par()函数将所绘制的线条设置为双倍宽度(lwd=2),这样它们在书中就会更易读❶。接下来载入了sm包,并绑定了数据框mtcars。
在数据框mtcars❷中,变量cyl是一个以4、6或8编码的数值型变量。为了向图形提供值的标签,这里cyl转换为名为cyl.f的因子。函数sm.density.compare()创建了图形❸,一条title()语句添加了主标题。
最后,添加了一个图例以增加可解释性❹。(图例已在第3章介绍。)首先创建的是一个颜色向量,这里的colfill值为c(2, 3, 4)。然后通过legend()函数向图形上添加一个图例。第一个参数值locator(1)表示用鼠标点击想让图例出现的位置来交互式地放置这个图例。第二个参数值则是由标签组成的字符向量。第三个参数值使用向量colfill为cyl.f的每一个水平指定了一种颜色。结果如图6-10所示。
如你所见,核密度图的叠加不失为一种在某个结果变量上跨组比较观测的强大方法。你可以看到不同组所含值的分布形状,以及不同组之间的重叠程度。(这段话的寓意是,我的下一辆车将是四缸的——或是一辆电动的。)
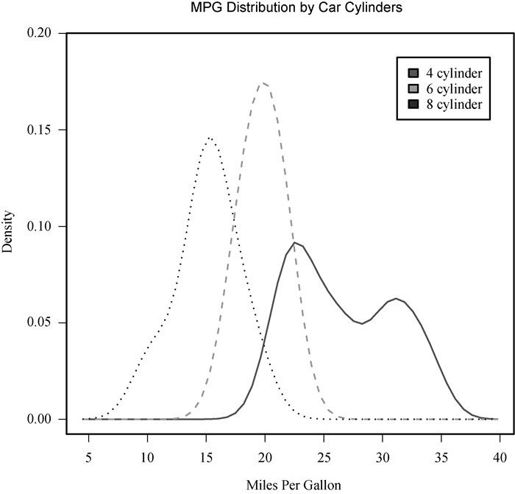
图6-10 按汽缸个数划分的各车型每加仑汽油行驶英里数的核密度图
箱线图同样是一项用来可视化分布和组间差异的绝佳图形手段(并且更常用),我们接下来讨论它。
