16.2 lattice包
lattice包为单变量和多变量数据的可视化提供了一个全面的图形系统。由于它可以轻松生成栅栏图形,因此许多用户都会使用它。
在一个或多个其他变量的条件下,栅栏图形展示某个变量的分布或与其他变量间的关系。考虑如下问题:纽约合唱团中歌手的身高随着他们所属的声部如何变化?
lattice包中的singer数据集包含了合唱成员的身高和声部数据。来看下列代码:
library(lattice)histogram(~height | voice.part, data = singer,main="Distribution of Heights by Voice Pitch",xlab="Height (inches)")
height是因变量,voice.part被称作条件变量(conditioning variable),这段代码对八个声部的每一个都创建一个直方图,见图16-1。图形显示男高音和男低音比女低音和女高音身高要高。
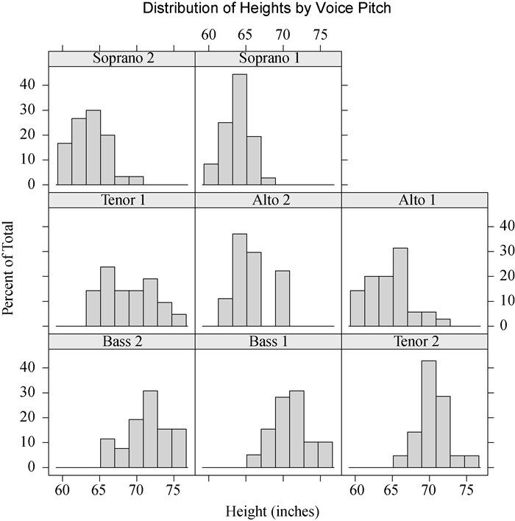
图16-1 以声部为条件的歌手身高栅栏图
在栅栏图形中,单个面板要依据条件变量的各个水平来创建。如果指定了多个条件变量,那么一个面板将按照各个因子水平的组合来创建。然后面板将被排成一个阵列以进行比较。每个面板在一个区域都会有一个标签,这里的区域称作条带区域(strip)。随后你将看到,用户可对每个面板中展示的图形、条带的格式和位置、面板的摆放、图例的内容和位置以及其他许多图形特征进行控制。
lattice包提供了丰富的函数,可生成单变量图形(点图、核密度图、直方图、柱状图和箱线图)、双变量图形(散点图、带状图和平行箱线图)和多变量图形(三维图和散点图矩阵)。
各种高级绘图函数都服从以下格式:
- graph_function(formula, data=, options)
graph_function是表16-2的第二栏列出的某个函数。formula指定要展示的变量和条件变量。data指定一个数据框。options是逗号分隔参数,用来修改图形的内容、摆放方式和标注。表16-3列出了一些常见的选项。
表16-2 lattice包中的图形类型和相应函数
| 图形类型 | 函 数 | 表达式示例 |
|---|---|---|
| 三维等高线图 | contourplot() | z ~ x*y |
| 三维水平图 | levelplot() | z ~ y*x |
| 三维散点图 | cloud() | z ~x*y|A |
| 三维线框图 | wireframe() | z~y*x |
| 条形图 | barchart() | x ~ A或A ~ x |
| 箱线图 | bwplot() | x ~ A或A ~ x |
| 点图 | dotplot() | ~ x|A |
| 直方图 | histogram() | ~ x |
| 核密度图 | densityplot() | ~ x|A*B |
| 平行坐标图 | parallel() | dataframe |
| 散点图 | xyplot() | y ~ x|A |
| 散点图矩阵 | splom() | dataframe |
| 带状图 | stripplot() | A ~ x或x ~ A |
*注意,在这些表达式中,小写字母代表数值型变量,大写字母代表类别型变量。 表16-3 lattice中高级绘图函数的常见选项
| 选 项 | 描 述 |
|---|---|
aspect | 数值,设定每个面板中图形的宽高比 |
col、pch、lty、lwd | 向量,分别设定图形中的颜色、符号、线条类型和线宽 |
Groups | 用来分组的变量(因子) |
index.cond | 列表,设定面板的展示顺序 |
key(或auto.key) | 函数,添加分组变量的图例符号 |
layout | 两元素数值型向量,设定面板的摆放方式(行数和列数);如有需要,可以添加第三个元素,以指定页数 |
Main、sub | 字符型向量,设定主标题和副标题 |
Panel | 函数,设定每个面板要生成的图形 |
Scales | 列表,添加坐标轴标注信息 |
Strip | 函数,设定面板条带区域 |
Split、position | 数值型向量,在一页上绘制多幅图形 |
Type | 字符型向量,设定一个或多个散点图的绘图参数(如p=点、l=线、r=回归、smooth=平滑曲线、g=格点) |
xlab、ylab | 字符型向量,设定横轴和纵轴标签 |
xlim、ylim | 两元素数值型向量,分别设定横轴和纵轴的最小和最大值 |
设小写字母代表数值型变量,大写字母代表类别型变量(因子)。在高级绘图函数中,表达式形式通常为:
y ~ x | A * B
在竖线左边的变量称为主要(primary)变量,右边的变量称为条件(conditioning)变量。主要变量将变量映射到每个面板的坐标轴上,此处,y ~ x表示变量分别映射到纵轴和横轴上。对于单变量绘图,用~ x代替y ~ x即可;对于三维图形,用z ~ x*y代替y ~ x,而对于多变量绘图(散点图矩阵或平行坐标图)用一个数据框代替y ~ x即可。注意,条件变量总是可以自行挑选的。
根据上述的逻辑,~ x | A即展示因子A各个水平下数值型变量x的分布情况;y ~ x | A*B即展示因子A和B各个水平组合下数值型变量x和y间的关系。而A ~ x则表示类别型变量A在纵轴上,数值型变量x在横轴上进行展示。~ x表示仅展示数值型变量x,更多例子可参考表16-2。
若想迅速浏览下lattice图形,可尝试运行代码清单16-1中的代码。图形是根据数据框mtcar中的小汽车数据(里程数、车重、挡位数、气缸数等)绘制而成。你也可以变换表达式,观察下结果有何不同。(为节省空间,此处略去了输出结果。)
代码清单16-1
lattice绘图示例
library(lattice)attach(mtcars)gear <- factor(gear, levels=c(3, 4, 5), # 赋予因子新的值标签labels=c("3 gears", "4 gears", "5 gears"))cyl <- factor(cyl, levels=c(4, 6, 8),labels=c("4 cylinders", "6 cylinders", "8 cylinders"))densityplot(~mpg,main="Density Plot",xlab="Miles per Gallon")densityplot(~mpg | cyl,main="Density Plot by Number of Cylinders",xlab="Miles per Gallon")bwplot(cyl ~ mpg | gear,main="Box Plots by Cylinders and Gears",xlab="Miles per Gallon", ylab="Cylinders")xyplot(mpg ~ wt | cyl * gear,main="Scatter Plots by Cylinders and Gears",xlab="Car Weight", ylab="Miles per Gallon")cloud(mpg ~ wt * qsec | cyl,main="3D Scatter Plots by Cylinders")dotplot(cyl ~ mpg | gear,main="Dot Plots by Number of Gears and Cylinders",xlab="Miles Per Gallon")splom(mtcars[c(1, 3, 4, 5, 6)],main="Scatter Plot Matrix for mtcars Data")detach(mtcars)
我们可以存储和操作lattice包中的高级绘图函数生成的图形。来看下列代码:
library(lattice)mygraph <- densityplot(~height|voice.part, data=singer)
它创建了一个栅栏密度图,并存储在mygraph对象中。但是此时不会展示任何图形,只有调用plot(mygraph)(或mygraph)时才会展示图形。
通过选项(options),你可以很轻松地修改lattice图形。表16-3列出了一些常见的选项,在本章后面你可以看到它们的许多应用示例。
在16.2.2节,你可以看到这些选项在高级函数或面板函数中的应用和讨论。
另外,你还可以使用update()函数来修改lattice图形对象。继续singer示例,来看下列代码:
update(mygraph, col=”red”, pch=16, cex=.8, jitter=.05, lwd=2)
将使用红色曲线和红色符号(color = "red")、填充的点(pch = 16)、更小(cex = .8)和更多高度扰动的点(jitter = .05),以及加粗的曲线(lwd = 2)来重新绘制图形。了解了高级lattice函数的一般结构后,下面我们来详细讨论条件变量。
16.2.1 条件变量
正如以上你所看到的,lattice图形的一个最强大之处便是可以添加条件变量。若添加一个条件变量,每个水平下都会创建一个面板。若添加两个条件变量,则会根据两个变量各个水平的组合分别创建面板。通常,没有必要添加两个以上的条件变量。
通常,条件变量是因子。但是,如果想以连续型变量为条件,该怎么办呢?一种方法是利用R的cut()函数将连续型变量转换为离散变量。另外,lattice包提供了一些将连续型变量转化为瓦块(shingle)数据结构的函数。特别地,连续型变量会被分割到一系列(可能)重叠的数值范围中。如函数:
- myshingle <- equal.count(x, number=#, overlap=proportion)
将会把连续型变量x分割到#区间中,重叠度为proportion,每个数值范围内的观测数相等,并返回为一个变量myshingle(或类shingle)。输出或者绘制该对象(如plot(myshingle))将会展示瓦块区间。
一旦一个连续型变量被转换为一个瓦块,你便可以将它作为一个条件变量使用。例如,用mtcars数据集来探究以发动机排量为条件时,每加仑英里数和车重的关系。由于发动机排量是一个连续型变量,首先需要将其转为一个三水平的瓦块变量:
displacement <- equal.count(mtcars$disp, number=3, overlap=0)
然后,在xyplot()函数中使用该变量:
xyplot(mpg~wt|displacement, data=mtcars,main = "Miles per Gallon vs. Weight by Engine Displacement",xlab = "Weight", ylab = "Miles per Gallon",layout=c(3, 1), aspect=1.5)
结果见图16-2。注意,此处我们使用了选项来修改面板的布局(三列和一行)和宽高比,这样更方便对三组进行比较。
比较图16-1和图16-2,你会发现面板的条带区域的标签有所不同。图16-2展示了条件变量的连续特性,深色表示每个面板中条件变量的取值范围。下节中,我们将使用面板函数进一步自定义输出结果。
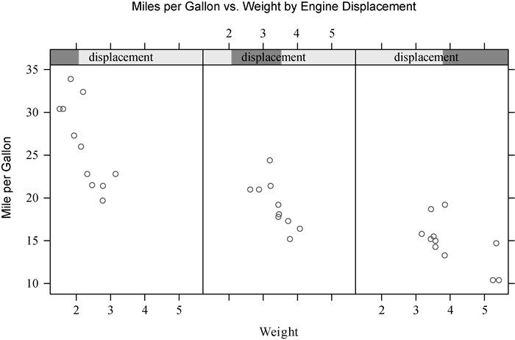
图16-2 以发动机排量为条件时加仑英里数与车重的栅栏图。由于发动机排量是一个连续型变量,因此将其转化为三个非重叠的、内部观测数相等的瓦块
16.2.2 面板函数
表16-2中的每个高级绘图函数都调用了一个默认的函数来绘制面板。这些默认的函数服从如下命名惯例:panel.graph_function,其中graph_function是该水平绘图函数。如:
xyplot(mpg~wt|displacement, data=mtcars)
也可以写成:
xyplot(mpg~wt|displacement, data=mtcars, panel=panel.xyplot)
这是一个非常强大的功能,因为它使你可以使用自定义函数替换默认的面板函数。你也可以将lattice包中的50多个默认面板函数中的某个或多个整合到自定义的函数中。自定义的面板函数具有极大的灵活性,你可以随意设计输出结果以满足要求。下面让我们来看一些示例。
之前的章节中,我们绘制了以发动机排量为条件时汽油英里数与车重的散点图。若想添加回归线、轴须线和网格线该怎么办呢?此时你便可以创建自己的面板函数(见代码清单16-2),图形结果见图16-3。
代码清单16-2 自定义面板函数的
xyplot
displacement <- equal.count(mtcars$disp, number=3, overlap=0)mypanel <- function(x, y) {panel.xyplot(x, y, pch=19) # ❶ 自定义面板函数panel.rug(x, y)panel.grid(h=-1, v=-1)panel.lmline(x, y, col="red", lwd=1, lty=2)}xyplot(mpg~wt|displacement, data=mtcars,layout=c(3, 1),aspect=1.5,main = "Miles per Gallon vs. Weight by Engine Displacement",xlab = "Weight",ylab = "Miles per Gallon",panel = mypanel)
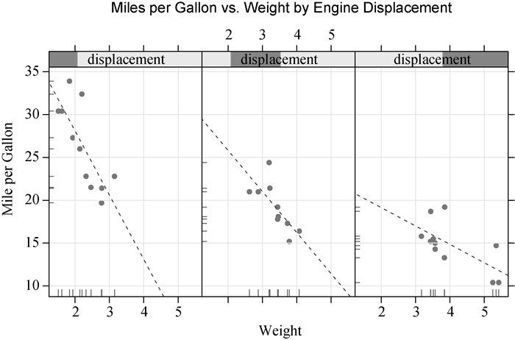
图16-3 以发动机排量为条件时每加仑英里数与车重的栅栏图。此处使用自定义的面板函数添加了回归线、轴须线和网格线
此处,我们将四个独立的绘制函数整合到自己的mypanel()函数中,然后通过xyplot()函数中的panel =选项将其展示出来❶。panel.xyplot()函数生成了填充圆圈(pch = 19)的散点图。panel.rug()函数在每个面板的x轴和y轴上添加了轴须线。panel.rug(x, FALSE)或panel.rug(FALSE, y)将分别只对横轴或纵轴添加轴须。panel.grid()函数添加了水平和竖直的网格线(使用负数强制它们与轴标签对齐)。最后,panel.lmline()函数添加了一条红色的(col="red")、标准粗细(lwd = 1)的虚线(lty = 2)回归线。每个默认的面板函数都有自己的结构和选项,更多细节可查看它们的帮助页(如help(panel.abline))。
第二个例子,我们将绘制以汽车传动类型为条件时每加仑英里数与发动机排量(连续型变量)的关系图。除了创建单独的自排和手排发动机的面板,我们还将添加平滑拟合曲线和水平均值线。代码见代码清单16-3。
代码清单16-3 自定义面板函数和额外选项的
xyplot
library(lattice)mtcars$transmission <- factor(mtcars$am, levels=c(0,1),labels=c("Automatic", "Manual"))panel.smoother <- function(x, y) {panel.grid(h=-1, v=-1)panel.xyplot(x, y)panel.loess(x, y)panel.abline(h=mean(y), lwd=2, lty=2, col="green")}xyplot(mpg~disp|transmission,data=mtcars,scales=list(cex=.8, col="red"),panel=panel.smoother,xlab="Displacement", ylab="Miles per Gallon",main="MGP vs Displacement by Transmission Type",sub = "Dotted lines are Group Means", aspect=1)
图形结果见图16-4。
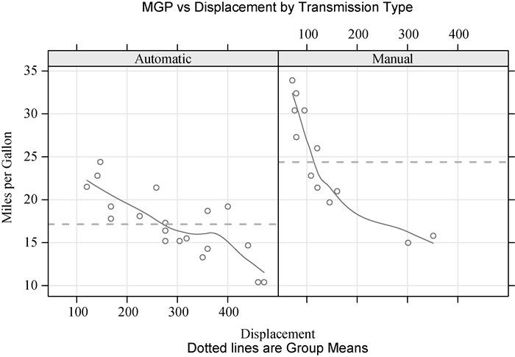
图16-4 以传动类型为条件时每加仑英里数与发动机排量的栅栏图。图中添加了平滑拟合曲线(loess)、网格线和组均值线
新代码中有一些地方需要注意。panel.xyplot()函数绘制了各个点,panel.loess()函数在每个面板中绘制了非参拟合曲线。panel.abline()函数在条件变量的各个水平下添加了mpg的均值线。(若用h = mean(mtcars$mpg)替换h=mean(y),那么将只绘制整个样本集的一个mpg均值参考线。)scales =选项将标度的标注修改为红色和80%的默认大小。
在上面的例子中,我们也可使用scales = list(x = list(), y = list())来分别设定横轴和纵轴的选项。参考help(xyplot)可获得更多关于标度选项的细节。下节我们将学习如何将分组观测整合到一起,而不是在各个面板中进行展示。
16.2.3 分组变量
当一个lattice图形表达式含有条件变量时,将会生成在该变量各个水平下的面板。若你想将结果叠加到一起,则可以将变量设定为分组变量(grouping variable)。
假使你想利用核密度图来展示手动挡和自动挡汽车的每加仑英里数的分布情况,可使用如下代码:
library(lattice)mtcars$transmission <- factor(mtcars$am, levels=c(0, 1),labels=c("Automatic", "Manual"))densityplot(~mpg, data=mtcars,group=transmission,main="MPG Distribution by Transmission Type",xlab="Miles per Gallon",auto.key=TRUE)
结果见图16-5。group =选项默认将分组变量各个水平下的图形叠加到一起。绘制的点为空心圆圈,线为实线,水平信息用颜色来区分。不过以灰色调输出时,颜色将很难区分。稍后我们将看看如何修改这些默认值。
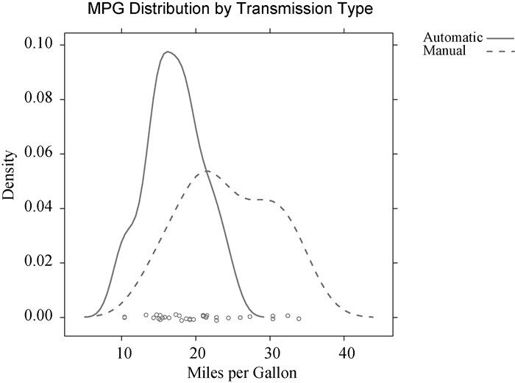
图16-5 以传动类型为分组变量时每加仑英里数的核密度曲线图。水平轴上还绘制了扰动点
注意图例或图例符号不会默认生成。选项auto.key = TRUE将可以创建一个摆放在图形上方的、初步的图例符号,你可将所做的修改以列表形式添加到自动图例符号中。例如:
auto.key=list(space=”right”, columns=1, title=”Transmission”)
将把图例移到图形的右边,并在一个单独的栏中展示符号和图例标题。
若你想对图例进行更多的控制,可使用key =选项。代码清单16-4给出了一个示例,结果见图16-6。
代码清单16-4 自定义图例并含有分组变量的核密度曲线图
library(lattice)mtcars$transmission <- factor(mtcars$am, levels=c(0, 1),labels=c("Automatic", "Manual"))colors = c("red", "blue") # ❶ 设定颜色、线和点类型lines = c(1,2)points = c(16,17)key.trans <- list(title="Trasmission", # ❷ 自定义图例space="bottom", columns=2,text=list(levels(mtcars$transmission)),points=list(pch=points, col=colors),lines=list(col=colors, lty=lines),cex.title=1, cex=.9)densityplot(~mpg, data=mtcars,group=transmission,main="MPG Distribution by Transmission Type",xlab="Miles per Gallon",pch=points, lty=lines, col=colors, # ❸ 自定义密度图lwd=2, jitter=.005,key=key.trans)
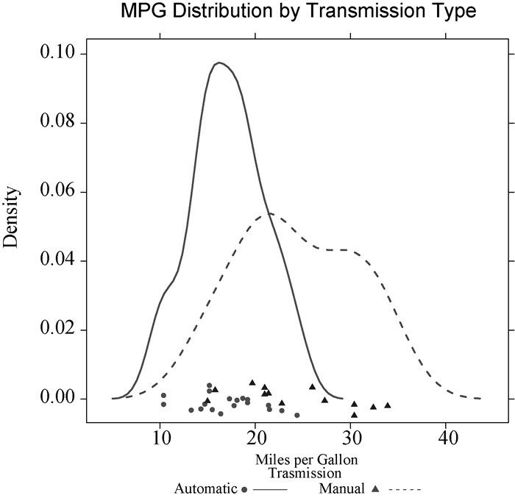
图16-6 以传动类型为分组变量时每加仑英里数的核密度图。已修改图形参数,并添加了一个自定义的图例,包括颜色、形状、线条类型、字符大小和标题的设定
此处,图形符号、线条类型和颜色都设定为向量❶。每个向量的第一个原色都会被应用到分组变量的第一个水平上,第二个元素应用到第二个水平上,以此类推❷。创建了一个图例选项的列表对象。选项设定了图例以两栏形式摆放在图形下方,并包含水平名称、点符号类型、线条类型和颜色。图例标题设置得比符号的文本稍大。
❸中的densityplot()函数使用了相同的绘图符号、线条类型和颜色,同时还增加了线条粗细和扰动程度以改善图形外观。最后,图例符号设置使用的是之前定义的列表值。这种为分组变量设定图例的方式具有很大的灵活性。实际上,你可以创建不止一个图例,并将它们摆放到图形不同的区域(此处不展示)。
本节结束之前,让我们再学习一个分组变量和条件变量同时包含在一幅图形中的例子。数据集使用的是R基础安装中的CO2数据框,它描述的是一个对稗草耐寒度的研究。
数据包含了12个植物(Plant)在七种二氧化碳浓度环境(conc)中的二氧化碳吸收率(uptake)。六个植物来自加拿大的魁北克省,另外六个来自美国的密西西比州。其中每组的三个植物处于严寒环境,另外三个处于非严寒环境。本例中,Plant是分组变量,而Type(魁北克省/密西西比州)和Treatment(严寒/非严寒)是条件变量。代码清单16-5生成的图形见图16-7。
代码清单16-5 包含分组变量和条件变量以及自定义图例的
xyplot
library(lattice)colors <- "darkgreen"symbols <- c(1:12)linetype <- c(1:3)key.species <- list(title="Plant",space="right",text=list(levels(CO2$Plant)),points=list(pch=symbols, col=colors))xyplot(uptake~conc|Type*Treatment, data=CO2,group=Plant,type="o",pch=symbols, col=colors, lty=linetype,main="Carbon Dioxide Uptake\nin Grass Plants",ylab=expression(paste("Uptake ",bgroup("(", italic(frac("umol","m"^2)), ")"))),xlab=expression(paste("Concentration ",bgroup("(", italic(frac(mL,L)), ")"))),sub = "Grass Species: Echinochloa crus-galli",key=key.species)
注意\n将会使标题分成两行,expression()函数将在坐标轴标签上添加数学符号。此例中将颜色作为分组的区分器,在col =选项中指定了一种颜色。不过添加12种不同的颜色会显得过于复杂,偏离在每个面板中直观展示变量关系的目标。从图中可以清楚地看到,密西西比州的稗草在严寒环境中的二氧化碳吸收率有些不同。
到目前为止,你已经学习了如何通过高级绘图函数中的选项(如xyplot(pch = 17))以及面板函数中的选项(panel.xyplot(pch = 17))来修改图形元素。但是这种修改只在函数调用期间有效,在下节中,我们将学习在整个交互期间或批次运行期间一直有效的图形参数修改方法。
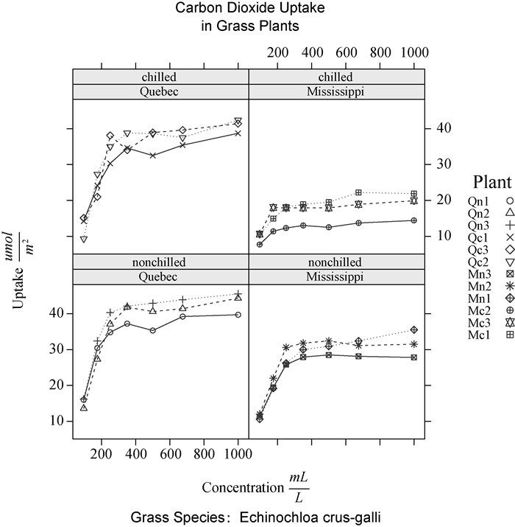
图16-7 xyplot展示了在两种处理条件下,两种类型的12个植物在不同二氧化碳浓度下的二氧化碳吸收率。Plant是分组变量,Treatment和Type是条件变量
16.2.4 图形参数
第3章中,我们学习了如何利用par()函数查看和设置默认的图形参数。不过它们只对R中简单的图形系统生成的图形有效,对于lattice图形来说这些设置是无效的。在lattice图形中,lattice函数默认的图形参数包含在一个很大的列表对象中,你可通过trellis.par.get()函数来获取,并用trellis.par.set()函数来修改。show.settings()函数可展示当前的图形参数设置情况。
以把默认图形符号修改为叠加点(即图形中包含了一个分组变量的点)为例,默认设置是空心圆圈,我们将赋予每组的点以各自的符号。
首先,查看当前的默认设置,并将它们存储到一个mysettings列表中:
> show.settings()> mysettings <- trellis.par.get()
然后,查看叠加点的默认设置值:
> mysettings$superpose.symbol$alpha[1] 1 1 1 1 1 1 1$cex[1] 0.8 0.8 0.8 0.8 0.8 0.8 0.8$col[1] "#0080ff" "#ff00ff" "darkgreen" "#ff0000" "orange" "#00ff00"[7] "brown"$fill[1] "#CCFFFF" "#FFCCFF" "#CCFFCC" "#FFE5CC" "#CCE6FF" "#FFFFCC" "#FFCCCC"$font[1] 1 1 1 1 1 1 1$pch[1] 1 1 1 1 1 1 1
此处你可以看到分组变量的每个水平都使用空心圆圈(pch = 1)。定义了7个水平后,图形符号将会被循环使用。
最后,我们再做如下声明:
mysettings$superpose.symbol$pch <- c(1:10)trellis.par.set(mysettings)show.settings()
此时lattice图形将对分组变量的第一个水平使用符号1(空心圆圈),第二个使用符号2(空心三角形),以此类推。另外,我们对分组变量的10个水平的符号都进行了定义,而不是7个。这种图形设置效果将会一直存在,直到关闭图形设备。你可以按照此方式对其他任意图形参数进行修改。
16.2.5 页面摆放
第3章中,我们学习了如何利用par()函数在一个页面中摆放多个图形。由于lattice函数不识别par()设置,因此你需要另辟蹊径。最简单的方法便是先将lattice图形存储到对象中,然后利用plot()函数中的split =或position =选项来进行控制。
split选项将页面分割为一个指定行数和列数的矩阵,然后将图形放置到该矩阵中。split选项的格式为:
- split=c(placement row, placement column,
- total number of rows, total number of columns)
来看以下代码:
library(lattice)graph1 <- histogram(~height|voice.part, data=singer,main="Heights of Choral Singers by Voice Part")graph2 <- densityplot(~height, data=singer, group=voice.part,plot.points=FALSE, auto.key=list(columns=4))plot(graph1, split=c(1, 1, 1, 2))plot(graph2, split=c(1, 2, 1, 2), newpage=FALSE)
它将把第一幅图放置到第二幅图的上面。具体来讲,第一个plot()函数把页面分割成一列两行的矩阵,并将图形放置到第一列、第一行中(自上往下、从左至右地计数)。第二个plot()函数做同样的分割,但是把图形放置到第一列、第二行中。因为plot()函数默认启动一个新的页面,所以你需要禁止该操作,因此设定选项newpage = FALSE。(篇幅所限,未画出图形。)
使用position =选项可以对大小和摆放方式进行更多的控制。考虑如下代码:
library(lattice)graph1 <- histogram(~height|voice.part, data=singer,main="Heights of Choral Singers by Voice Part")graph2 <- densityplot(~height, data=singer, group=voice.part,plot.points=FALSE, auto.key=list(columns=4))plot(graph1, position=c(0, .3, 1, 1))plot(graph2, position=c(0, 0, 1, .3), newpage=FALSE)
来看此处的position = c(xmin, ymin, xmax, ymax),该页面的x-y坐标系统是矩形,x轴和y轴的维度范围都是从0到1,原点(0, 0)在图形左下角。(篇幅所限,未画出图形。)
在lattice图形中你还可以改变面板的顺序。高级绘图函数的index.cond =选项可以设定条件变量水平的顺序。以voice.part因子为例,因子水平有:
> levels(singer$voice.part)[1] "Bass 2" "Bass 1" "Tenor 2" "Tenor 1" "Alto 2" "Alto 1"[7] "Soprano 2" "Soprano 1"
添加的index.cond = list(c(2, 4, 6, 8, 1, 3, 5, 7))将把1声部放在一起,随后是2声部。当有两个条件变量时,在列表中包含两个向量即可。在代码清单16-5中,添加的index.cond=list(c(1, 2), c(2, 1))将会翻转图16-7处理方式的顺序。
如果想更深入地了解lattice图形,可以查阅Sarkar(2008)所写的优秀教材,以及相应的网站http://lmdvr.r-forge.r-project.org。栅栏图形的用户手册(http://cm.bell-labs.com/cm/ms/departments/sia/doc/trellis.user.pdf)也是一个非常好的学习资源。
下一节将探究另一个能够全面替代R原生图形系统的包:ggplot2。
