1.4 网页的文本内容
元素中包含的文本可能是网页上最基本的成分。如果你用过文字处理软件,那么你一定输入过文本。不过,HTML页面中的文本有一些重要的差异。
首先,浏览器呈现HTML时,会把多个空格或制表符压缩成单个空格,并把回车和换行符转换成单个空格,或者将它们一起忽略,如图1.4.1和图1.4.2所示。
<p>I am continually <em>amazed</em> at the beautiful, delicate Blue Flax that somehow took hold in my garden.They are awash in color every morning, yet not a single flower remains by the afternoon.They are the very definition of ephemeral.</p><p>© Blue Flax Society.</p>
图1.4.1 页面的文本内容(粗体部分)几乎就是标记以外的所有东西。在这个例子里面,注意每个句子都至少包含一个回车,有的词之间隔了好几个空格(为了说明对回车和空格的压缩)。另外,这里还包含一个表示版权符号的特殊字符引用(©),这样做可以确保无论以哪种编码方式保存这份文档,这个符号都会被正确地显示
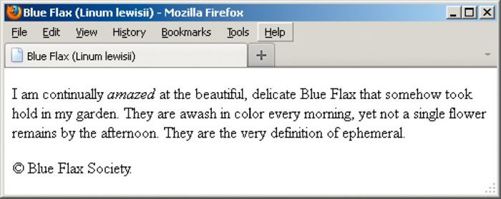
图1.4.2 注意,在使用浏览器查看这份文档时,多余的回车和空格都被忽略了,字符引用被替换成了对应的符号(©)
其次,HTML过去只能使用ASCII字符。ASCII只包括英语字母、数字和少数几个常用的符号。重音字符(在很多西欧语言中很常见)和许多日常符号必须用特殊的字符引用来创建,如é(表示é)、©(表示©)等。完整列表见www.elizabethcastro.com/html/extras/entities.html。
Unicode大大减轻了特殊字符问题的负担。用UTF-8对页面进行编码(如基本页面那样,参见图1.4.3),并用同样的编码保存HTML文件(参见2.3节)已成为一种标准做法。推荐你也这样做。
<!DOCTYPE html><html lang="en"><head><meta charset="utf-8" /><title>Blue Flax (Linum lewisii)</title></head><body>...</body></html>
图1.4.3 直接在head开始标记后面指明文档的字符编码。charset属性用以设置编码类型
由于Unicode是ASCII的超集(它包含ASCII中的所有字符,还包含许多其他的字符),因此用Unicode编码的文档与现有的浏览器和编辑器都兼容(特别旧的除外)。不理解Unicode的浏览器会正确地解释文档的ASCII部分,而理解Unicode的浏览器还会显示非ASCII部分。即便如此,有时还是会使用字符引用,如版权符号(因为©既好记又好输入),如图1.4.1所示。
