2.3 常用的连续分布
在六西格玛管理中,最常用的连续型分布有:
(1)正态分布(normal distribution)
(2)均匀分布(uniform distribution)
(3)指数分布(exponential distribution)
(4)对数正态分布(lognormal distribution)
(5)威布尔分布(Weibull distribution)
此外,还有很多分布在管理、经济、社会、卫生、教育等领域有广泛应用,MINIT-AB为此提供了全面选择的机会。总共包括下列这些:
(6)三角形分布(triangular distribution)
(7)Beta分布(beta distribution)
(8)Cauchy分布(Cauchy distribution)
(9)Gamma分布(Gamma distribution)
(10)Laplace分布(Laplace distribution)
(11)Logistic分布(Logistic distribution)
(12)对数Logistic分布(Loglogistic distribution)
(13)最大极值分布(largest extreme distribution)
(14)最小极值分布(smallest extreme distribution)
在统计推断中还有三种连续型分布极其重要,但是它们本身并没有太多的直接应用。由于这三种分布都是在正态分布的假定下推导出来的,因此它们常被称为是“导出分布”,这里有:T分布、F分布以及卡方(Chi-Square)分布。对这三种分布将在第4章中作详细介绍,本章就不再赘述,只在表2—10中一并列出。
以下分小节予以介绍。
2.3.1 正态分布
质量管理中最常遇到的连续分布是正态分布,很多质量特性X都可以用正态分布来描述其取值的规律性。数学理论上可以证明,如果某项指标受到很多项随机因素的干扰,而每项干扰都很小的话,则所有干扰影响的综合结果将导致此项指标的分布为正态分布。事实上,很多生产过程的最终指标都具有这种特点,因此相当多的随机变量本身都应该是正态分布。但也有些随机变量就不是这样,例如“寿命”的形成就不是这样的机理,所以绝大多数的寿命都是严重的正偏分布(右边尾部会很长),所以可靠性分析中的常用分布就是另外一类了。
一般正态分布的概率密度函数为:

正态分布又称高斯(Gauss)分布,虽然早在18世纪及以前有很多学者已经知道这种分布的样子,但它是由德国数学家高斯于1809年正式给出了表达式的。为了纪念高斯的伟大贡献,在德国10马克的钞票上不但印上了高斯的头像,而且把正态密度曲线连同式(2—17)印在钞票的正面(见图2—24)。

图2—24 德国10马克钞票正面图
在这里我们约定,式(2—17)密度表达式中竖线后面的几个字母代表此分布的相应参数,例如正态分布就有μ及σ2两个参数。其概率密度函数曲线可形象地描述为“中间高、两边低、左右对称、延伸到无穷”的钟形曲线,如图2—25所示。
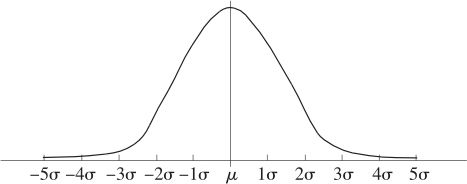
图2—25 一般正态分布概率密度图
一般正态分布用符号N(μ,σ2)表示,其中,μ是正态分布的均值,给出了正态分布的中心,X在μ附近取值的机会较大。σ2是正态分布的方差,σ>0是正态分布的标准差,它代表数据的分散状况。μ取值的不同,反映的是位置的不同,后面的图(见图2—28)中显示的是N(1,1)及N(3,1)的密度图。在MINITABR15中增加了绘制总体密度图的功能,我们可以充分利用。
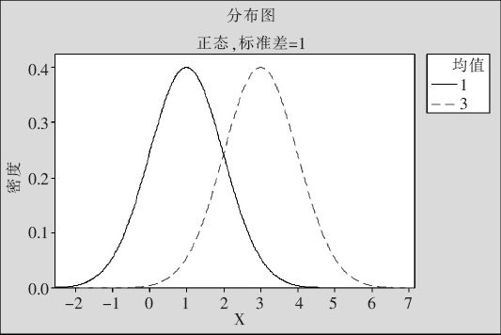
图2—28 均值不等但方差相等的正态曲线比较图
从“图形>概率分布图(Graph>Probability Distribution Plot)”入口,选中“不同参数(Vary Parameter)”,其操作示意参见图2—26。
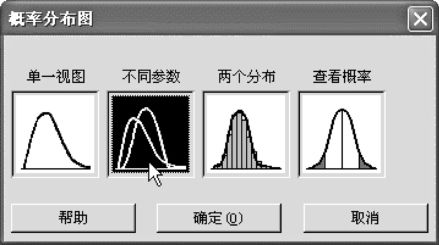
图2—26 同时显示多条概率密度图
这时将跳出分布类型的选择窗(参见图2—27),选择“正态(Normal)”。填写有关参数,并选择“确定”后,则可以在同一张图中显示出两条均值不等、方差相等的正态曲线(见图2—28)。
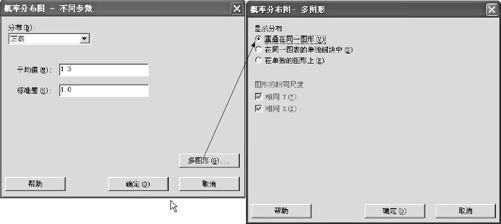
图2—27 选定分布并要求重叠显示操作图
用几乎相同的操作,可以绘制出均值相等(都为5)但方差不等(σ=1,σ=2及σ=3)的正态曲线比较图(见图2—29)。
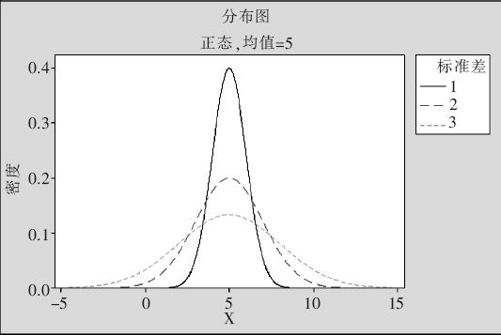
图2—29 均值相等但方差不等的正态曲线比较图
我们把μ=0且σ=1的特殊正态分布称为标准正态分布(standard normal distribution),记为N(0,1)。它在统计理论中有着关键的地位(见图2—30)。
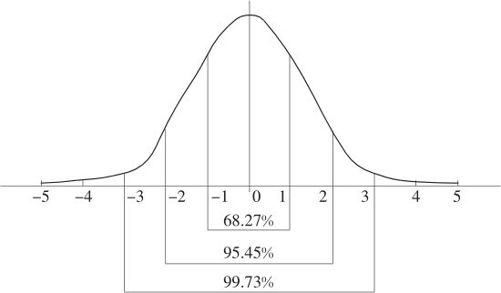
图2—30 标准正态分布密度曲线图
更详细的结果是这样的:
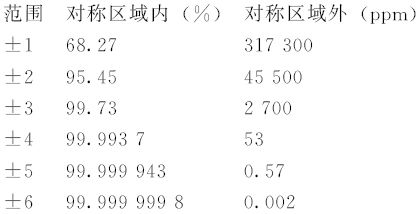
对于一般正态分布概率计算依赖于下列重要的公式:
设X的分布是正态分布N(μ,σ2),即X~N(μ,σ2),令

则Z~N(0,1)。我们称Z为X所对应的“Z值”(即标准化正态值)。其示意图见图2—31。
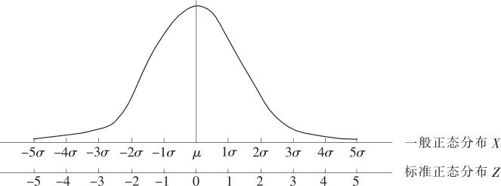
图2—31 一般正态分布的标准化示意图
由于正态分布的密度积分不能表达为一般的公式,计算起来就非常困难,因此式(2—18)就是计算一般正态分布概率必须熟练掌握的工具,但在计算机软件发达的今天,我们可以直接计算一般正态分布概率之值,不一定要用此公式,但它的概念仍非常重要,尤其在六西格玛管理中,它就是我们通常使用的Z值。
与Z值相联系的分布就是标准正态分布函数表。在本书的附表1中就给出了它们的数值。有关正态概率的计算,读者可以直接查表求得,也可以使用计算机软件来进行。
例2—7(续例2—6)
中国成年男子身高均值为168cm,标准差为5.5cm。试计算:
(1)身高小于160cm的概率。
(2)身高高于180cm的概率。
(3)身高介于160cm~180cm的概率。
解 在例2—6中,给出了用计算机软件计算的方法。下面用手算的方法,这将使我们对正态分布的性质有更深入的理解。
(1)身高小于160cm的概率:
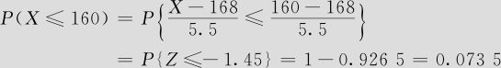
(2)身高高于180cm的概率:
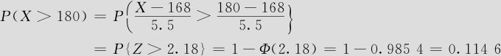
(3)身高介于160cm~180cm的概率:
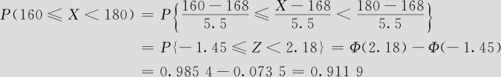
这里与原来用计算机直接计算结果0.9121有些差别,原因是我们在除法时有舍入误差,将-1.4545舍为-1.45以及将2.1818舍为2.18都造成了查表的误差,致使最后结果也有了微小的误差。这说明直接用软件计算既方便又准确。
正态分布有很多很有用的性质,例如,两个正态分布随机变量之和一定也是正态分布。具体说来:
(1)如果X~N(μ1,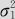 ),Y~N(μ2,
),Y~N(μ2,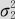 ),而且二者独立,则
),而且二者独立,则

(2)如果X~N(μ1,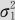 ),Y~N(μ2,
),Y~N(μ2,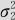 ),且已知二者相关,相关系数为ρ,则
),且已知二者相关,相关系数为ρ,则
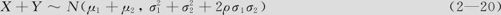
可以看出式(2—20)比式(2—19)意义更广泛:当X与Y相互独立时,当然二者不相关(反之不对,对于一般的二元随机分布,不相关不能保证独立;但对于正态分布,独立与不相关是一回事),因此,ρ=0,式(2—20)就自动变为式(2—19)。
(3)如果X~N(μ1,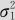 ),Y~N(μ2,
),Y~N(μ2,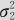 ),二者相关,相关系数为ρ,设a,b为任意常数,则
),二者相关,相关系数为ρ,设a,b为任意常数,则
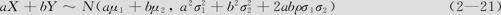
特别地,如果X与Y相互独立,则

其实,式(2—22)可以推广到更多的随机变量情况。在多个随机变量情况下,下面的结果最常用:
(4)如果X1,X2,…,Xn相互独立,且分布都是N(μ,σ2),则
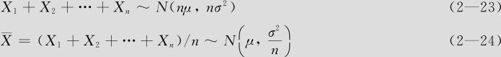
2.3.2 均匀分布
如果连续型随机变量X落入区间(a,b)间的概率密度为常数,则称X在区间(a,b)上服从均匀分布,记为X~U(a,b),其密度函数见式(2—25),其密度图形如图2—32所示。

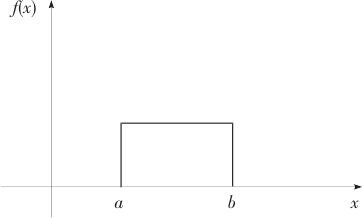
图2—32 均匀分布密度图
例如,一只轮子上,原来标有水平箭头(见图2—33左),飞快旋转中突然让它停转,原来的水平箭头线会停留何处(见图2—33右)?如果记它旋转了的角度为X(以弧度为单位),则X是在[0,2π]上的均匀分布,其密度函数见式(2—26)。
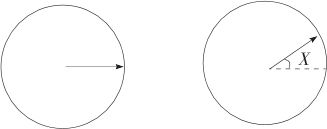
图2—33 轮子旋转形成均匀分布密度图

又比如,在将计算过程中的中间结果进行四舍五入取整时,有的数因此而变大些,有些则变小些,其舍入误差是在区间[-0.5,0.5]上的均匀分布;在将计算中间结果进行四舍五入保留一位小数时,其舍入误差是区间[-0.05,0.05]上的均匀分布。
均匀分布U(a,b)的均值、方差分别为:

2.3.3 指数分布
指数分布是一种常见的连续分布,它在研究寿命分布方面有特别重要的意义。其概率密度函数为:

此式还有另一种形式:

其分布密度曲线如图2—34所示。
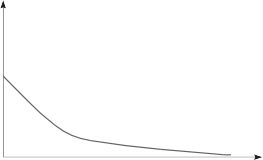
图2—34 指数分布密度图
密度为式(2—28)或式(2—29)的随机变量X称为服从指数分布。容易看出这两个公式其实是一回事,只要令λ=1/b就行了(当然这里λ,b都必须是正数)。这两种表达方式各有其物理意义。指数分布中的参数写为式(2—29)中的λ,它代表瞬时失效率,也就是一个元器件今日尚在工作,明日突然失效的概率。例如已知某电视机瞬时失效率为λ=0.0001/天(瞬时失效率的量纲是时间倒数),表示此电视机今日尚在工作,明日失效的概率为万分之一(以天为时间单位)。指数分布中的参数写为式(2—28)中的b,它称为“尺度参数”。数学上可以证明:如果瞬时失效率永远不变而保持常数λ时,则此元器件寿命一定是服从指数分布。若记其平均寿命μ,则有下列公式:b=μ=1/λ,就是说b的含义是平均寿命。在上述电视机的例子中,由于瞬时失效率为λ=0.0001/天,则平均寿命为μ=b=1/λ=10000天(≈27年)。在MINITAB中,对于指数分布通常使用尺度参数b。
对于电视机寿命的分布密度图可以参见图2—35,这里我们用的是尺度参数b=10000。在这种简单情况下,平均寿命μ=b。
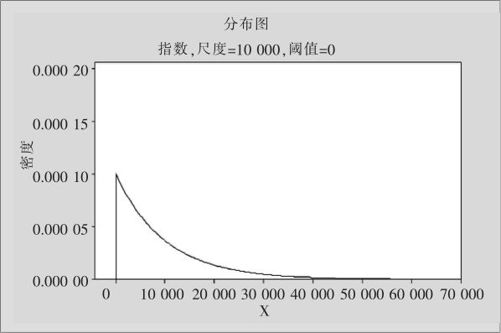
图2—35 电视机寿命分布密度图
一般元器件的失效规律应该是什么样的?其实大家对此是有经验的。例如,电视机寿命通常有几十年,一台电视机使用了2年或3年之后,由于造成此时出现失效的只可能是偶然原因,因此可以认为使用了2年或3年之后瞬时失效率是相同的。一般而言,元器件有早期失效期(越在开始使用阶段越容易失效),还有老年的耗损失效期(太老的元器件会随使用时间的增加而使瞬时失效率增长)。在此之间的正常工作期限内,其失效原因完全是偶然因素造成的,可以假定瞬时失效率与时间是无关的,因而它可以维持一个常数。总之,瞬时失效率大体上应该呈现浴盆曲线(bath-tubcurve),其示意图见图2—36。
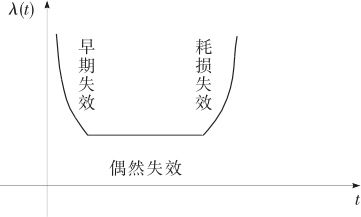
图2—36 元器件瞬时失效率的浴盆曲线图
如果只考虑中间瞬时失效率保持常量的这个阶段,则可以认为寿命服从指数分布。指数分布有两个重要结论:
(1)在指数分布中,失效率λ与尺度参数b二者互为倒数。
(2)在单参数指数分布(只含一个尺度参数)中,标准差σ与尺度参数b及平均寿命μ相同。即
σ=b=μ=1/λ
这也就是说,对于服从单参数指数分布的随机变量X的均值、方差分别为:

在实际工作生活中,不少产品首次发生故障的时间或发生故障后需要维修的时间都可以认为是服从指数分布的。
从图2—34或图2—35中可以看出,单参数指数分布是以原点为其开始点的。实际上,我们应该增加考虑此分布从某个阈值(threshold)开始。在MINITAB中,此值有时也称为“下界”。带有阈值T的指数分布称为“双参数指数分布”,其密度是式(2—31):

这表示,寿命最短也有T,寿命失效至少要从T时刻开始。与式(2—28)相比,服从双参数指数分布的随机变量X的方差与式(2—30)相同,期望则稍有差别:

例2—8
某公司生产的二极管的寿命服从阈值是500(小时),尺度是1000(小时)的指数分布。求其平均寿命及寿命的标准差。
解 其密度表达式为式(2—31):

其密度图形见图2—37。
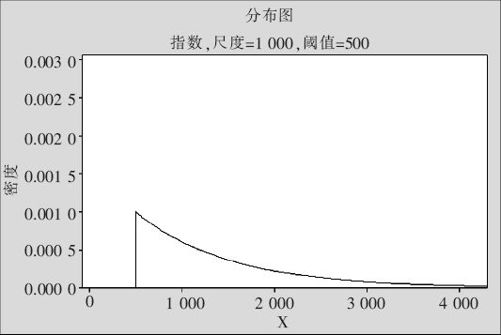
图2—37 带阈值的双参数指数分布密度图
将参数值代入式(2—32)可得平均寿命为1500小时,代入式(2—30)下半式,可得其标准差为1000小时。
2.3.4 对数正态分布
如果随机变量X只取正数值,而取自然对数后,lnX服从正态分布,则称X服从对数正态分布。对数正态分布出现在很多领域,如某些电器的寿命、化学反应时间、混凝土的强度、针刺麻醉的镇痛效果、流行病的蔓延时间、绝缘材料的被击穿电压等。在机床维修中,大量机床在短时间内都可修理好,但有少量机床需要长时间维修,个别机床可能需要更长的维修时间,因此机床维修时间常常是对数正态分布。其分布密度的表达式为:

这时,lnX~N(μ,σ2)。我们称μ为位置参数,称σ为尺度参数。其分布密度的图形显示为图2—38,从中可以看出,服从对数正态分布的随机变量X的大量取值(“大头”)在左侧,长尾在右侧,虽然尾巴很细但拖得很长,随机变量X所取数值非常分散,这样的分布属于典型的“正偏分布”(见图2—38)。
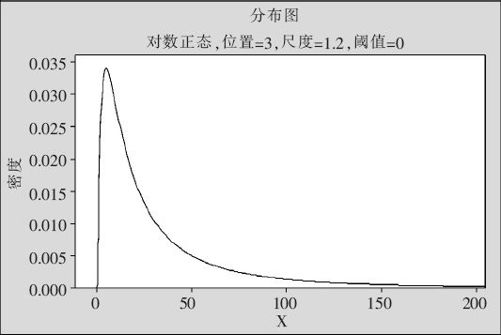
图2—38 对数正态分布密度图
对数正态分布的均值和方差为:

对数正态分布也可以有第3个阈值参数T,作为分布的起始点。
2.3.5 Weibull分布
Weibull分布是寿命试验和可靠性理论的基础,它是瑞典科学家威布尔(Waloddi Weibull)于1939年为描述材料强度而发现的一种分布,现都以其名字命名此分布。此分布的重要意义在于,对于瞬时失效率处于浴盆曲线的三个阶段,其寿命的分布都可以统一用Weibull分布给出。有关细节将在可靠性讨论中给出。
Weibull分布的概率密度函数为:

Weibull分布比指数分布有更广泛的适应性。式(2—36)中,a>0为尺度参数,b>0为形状参数。式(2—36)给出的是两参数的Weibull分布,记为X~W(a,b)。如果用f(x)和F(x)分别表示一个分布的密度函数和分布函数,称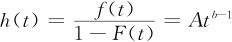 为瞬时失效率函数。当b=1时,h(t)是个常数,这一时期失效是属于“偶然失效”,这就是指数分布;当b<1时,h(t)随t的增长而下降,正好代表“早期失效”状况;当b>1时,h(t)是个递增函数,正好代表“耗损失效”的状况。尺度参数a起到放大与缩小比例常数的作用。因此,Weibull分布是描述可靠性的最理想的分布函数。
为瞬时失效率函数。当b=1时,h(t)是个常数,这一时期失效是属于“偶然失效”,这就是指数分布;当b<1时,h(t)随t的增长而下降,正好代表“早期失效”状况;当b>1时,h(t)是个递增函数,正好代表“耗损失效”的状况。尺度参数a起到放大与缩小比例常数的作用。因此,Weibull分布是描述可靠性的最理想的分布函数。
对于两参数a,b的Weibull分布,其数学期望和方差分别为:
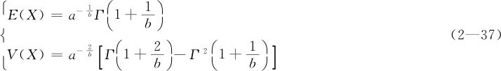
如果分布的起始点不为0,可以设定第三个参数:阈值参数(也称为位置参数)。阈值参数T是一个平移参数,有时又称为最小保证寿命,产品在时刻T以前是不会失效的。
图2—39显示的是尺度参数保持不变,而形状参数变化时(只显示了b>1)的分布密度状况。显然形状参数b=1就是我们熟悉的指数分布。
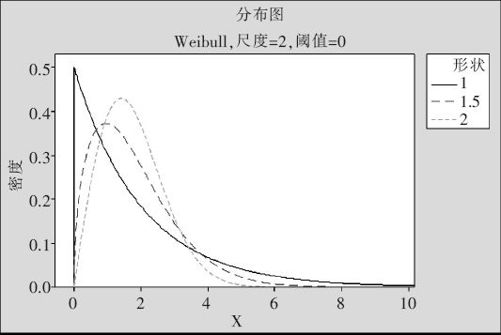
图2—39 Weibull分布(尺度参数固定)的分布密度图
2.3.6 三角形分布
顾名思义,三角形分布就是分布密度呈现三角形的分布。
这种分布要指定三个参数:下端点、上端点及众数。比如图2—40就是在[2,5]区间上,众数(密度最高处)为3的三角形分布。
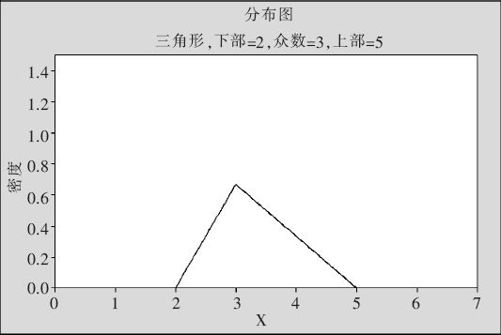
图2—40 三角形分布密度图
三角形分布在实际工作中也常用到。在六西格玛管理中,为了估计改进方案的效果,常进行计算机模拟试验。对于可能产生误差的因子,计算机有规律地产生大量随机数,以这些来模拟实际运转情况,最后以输出结果作为实际试验结果来进行评价分析,这就是随机模拟试验(或称蒙特卡罗方法)。这种随机模拟试验方法可以大大节省时间和试验费用,而且避免了可能造成的试验失败的经济损失,是很有前途及推广价值的。对于实际参数的取值,很常见的一种就是设定此参数为某段指定位置上的三角形分布。
2.3.7 Beta分布
在实际工作中也常用到取值为[0,1]范围的随机变量。例如,产品的不良率p肯定介于[0,1]之间。如果我们把不良率p看成是可以随机取值的随机变量,则可以讨论它的可能的分布密度,而Beta分布则可以作为p的分布密度(比如在随机模拟试验时)。其分布密度由式(2—38)给出,其中,a,b是该分布的两个参数:
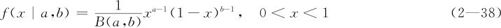
当两个参数a,b取不同值时,其密度曲线也不相同。当a=b=1时,其密度曲线为常数,代表[0,1]上的均匀分布;当a>1且b>1时,曲线上凸(见图2—41,这里显示的是a=2,而b分别取2及取5的两条曲线)。
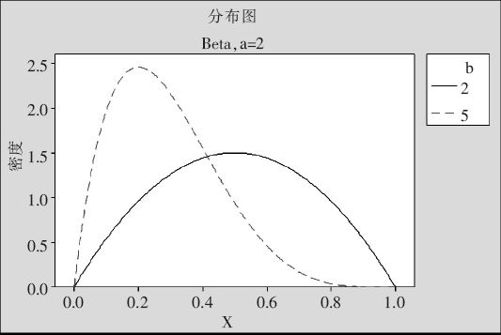
图2—41 Beta分布分布密度图(当a>1且b>1时)
当a<1且b<1时,曲线下凸(见图2—42,这里显示的是a=0.9,而b分别取0.6,0.95的两条曲线)。
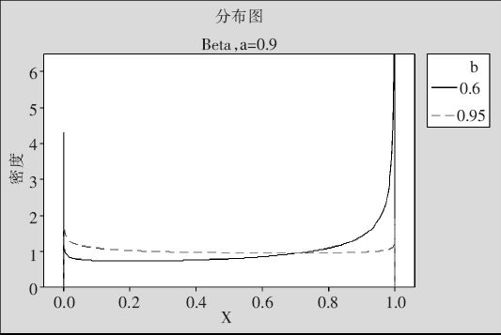
图2—42 Beta分布分布密度图(当a<1且b<1时)
当a>1且b<1时,曲线呈现J形(见图2—43,这里显示的是a=2,而b分别取0.7,0.9的两条曲线)。
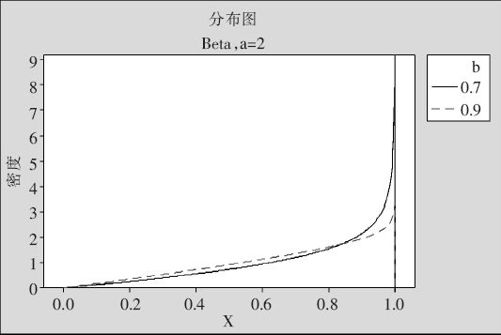
图2—43 Beta分布分布密度图(当a>1且b<1时)
当a<1且b>1时,曲线呈现L形(见图2—44,这里显示的是b=1.5,而a分别取0.4,0.8的两条曲线)。
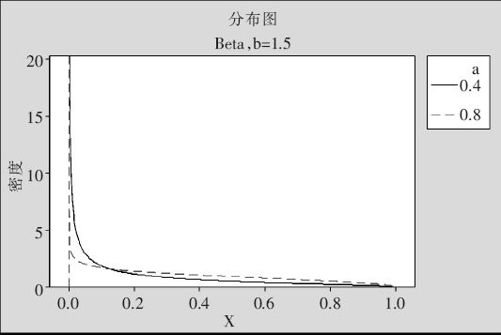
图2—44 Beta分布的分布密度图(当a<1且b>1时)
Beta分布数学期望和方差分别为:

2.3.8 Cauchy分布
在实际工作中也常用到取值非常分散的连续型分布,其代表之一就是Cauchy(柯西)分布。其最初来源是出自两个标准正态分布之比。可以设想,每个标准正态分布的均值是0,标准差是1,这样两个随机变量之比值肯定会满天乱飞,完全不着边际。其分散之严重是不难想象的。其分布密度公式(a>0)为:

此分布两端无限延伸。由于它太分散了,以至于它的均值都不存在(它只有中位数,即对称中心),它的方差就更不存在了。其密度图形见图2—45。
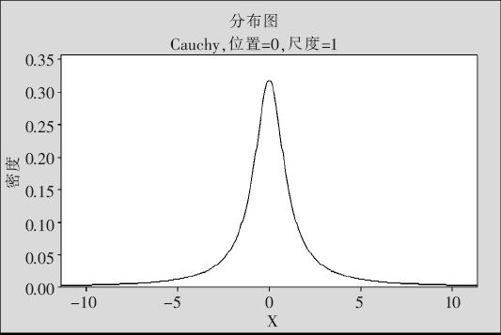
图2—45 Cauchy分布密度图
此图是对尺度参数a选为1画的,尺度参数变大些时,会更加分散。还应提到的另一个事实是,以后提到的t分布还与Cauchy分布有关,自由度为1的t分布其实就是参数a=1的标准Cauchy分布。
与其他很多分布相同,Cauchy分布也可以有第2个位置参数T,作为其分布的对称中心。
2.3.9 Gamma分布
自然界中很多随机变量的分布都是正偏态的。比如,在水文气象的研究中,年降雨量、年最高水位、风速、波高等,它们的分布与正态偏离很大,用Gamma(伽玛)分布来描述是很合适的。Gamma分布是包含两个参数的一族分布,它的适应性很广,不同的参数取值使得其密度出现复杂变化。两参数的Gamma分布之密度函数为:
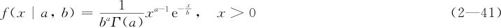
密度函数表达式中的Γ(a)是Gamma函数。这里要注意的是:Gamma函数Γ(a)与Gamma分布是完全不同的概念。Gamma函数的定义是下列将a作为参数的定积分,见式(2—42):

当a为正整数时,Γ(a)=(a-1)!,即它是a-1的阶乘,例如,Γ(2)=1,Γ(3)=2,Γ(4)=6,…。
Gamma函数Γ(a)考虑的是在式(2—42)中,以a为自变量的变化状况;Gamma分布则是在式(2—41)中,考虑在a,b等参数取固定值的条件下,x变化时的分布规律。所以,Gamma函数Γ(a)与Gamma分布讨论的是不同问题,完全是两回事。
在统计学中有重要地位的自由度为n的卡方分布是Gamma分布的特例(a=n/2,b=2);指数分布也是它的特例(a=1);伽玛分布又是a个(a为整数)服从指数分布的随机变量和的分布,因此可以说,Gamma分布是非常有用的一族分布。图2—46显示了a=2的几组分布图形。
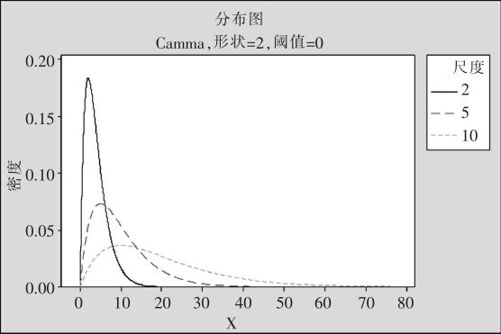
图2—46 Gamma分布密度图
两参数的Gamma分布的数学期望和方差为:

与对数正态分布及Weibull分布相同,Gamma分布也可以有第3个阈值参数T,作为分布的起始点。其期望为E(X)=ab+T,方差则保持与式(2—43)中的结果相同。
2.3.10 Laplace分布
18世纪中期,人们对于大量测量结果中的误差分布规律进行了多方面的探讨。拉普拉斯(Laplace)考虑到误差出现正负的可能性应该相同,在拟合多个观测值的线性规律时,应该使绝对误差的平均值达到最小,于是他在1772年(远在高斯于1809年提出正态分布以前)提出了Laplace分布。单参数Laplace分布密度公式是:

式中,b是尺度参数。其图形见图2—47。
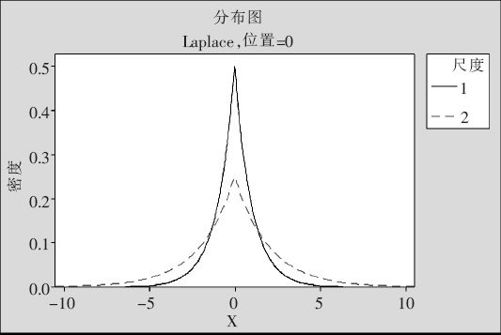
图2—47 Laplace分布密度图
容易看出,Laplace分布其实就是由左右两边都是指数分布“拼合”而成的。尺度参数b的不同值将使分布分散的程度有所不同。
单参数Laplace分布的数学期望和方差为:

与其他很多分布相同,Laplace分布也可以有第2个位置参数T作为其分布的对称中心。这时分布的期望为E(X)=T,方差则保持与式(2—45)中的结果相同。
2.3.11 Logistic分布
实际生活中常常有这种状况:某个数量(例如中国彩色电视机的销售量)先有明显的增长趋势(20世纪90年代前),趋于饱和后,销售量逐渐呈现下降趋势。服用药物后,身体内此种药物的存留量也是在达到高潮后逐渐回落。但这些数量升降的速度远比正态要缓慢、延迟。Logistic分布就是这样的分布,样子像正态分布,但降落非常慢,它在数学上更易于处理。设X是服从Logistic分布的随机变量,其概率密度函数是:
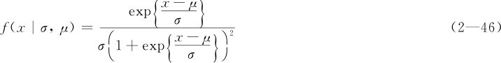
式中,σ是尺度参数;μ是位置参数。其分布密度的图形如图2—48所示。

图2—48 Logistic分布密度图
从表面上看,它与正态分布很相似,但它的两侧尾部的下降速度是指数级(e-x),与指数分布速度相仿;远比正态分布的“平方指数级”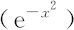 要慢得多;但它又远比Cauchy分布的“二次幂级”(x-2)要快得多。其均值和方差分别为:
要慢得多;但它又远比Cauchy分布的“二次幂级”(x-2)要快得多。其均值和方差分别为:

由于Logistic分布在可靠性中有十分重要的地位,我们将在本书的姐妹篇《基于MINITAB的现代实用统计》(见参考文献[21])的第8章“常用寿命分布及其识别”内做更详细的介绍。
2.3.12 对数Logistic分布
若Y=lnX是服从Logistic分布的随机变量,则X称为对数Logistic分布。其概率密度函数是:
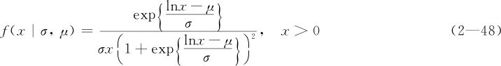
式中,μ和σ分别为位置参数和尺度参数。
它的分布密度的图形如图2—49所示。
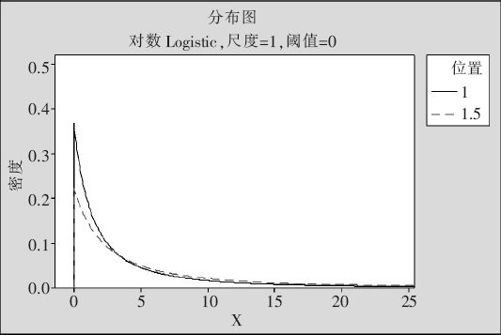
图2—49 对数Logistic分布密度图
对数Logistic分布的均值和方差分别为:
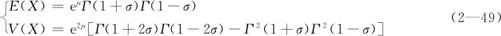
同样,在对数Logistic分布函数中,用t-T代替t,则两个参数的对数Logistic分布就扩展成了三参数(增加了阈值参数T)对数Logistic分布。其概率密度函数是:
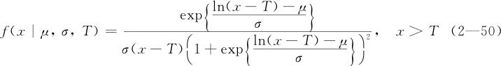
式中,μ和σ分别为位置参数和尺度参数;T为阈值参数。
三参数对数Logistic分布的均值为eμΓ(1+σ)Γ(1-σ)+T,其方差与式(2—49)结果相同。
由于二参数及三参数的对数Logistic分布在可靠性中也有十分重要的地位,我们将在本书的姐妹篇《基于MINITAB的现代实用统计》(见参考文献[21])的第8章“常用寿命分布及其识别”内做更详细的介绍。
2.3.13 最大极值分布
我们先看一个自然界中的例子。大海波涛汹涌,在修建水工建筑物或在海洋中航行必须要考虑到波浪的高度。通常我们取年最大波高分布中“50年一遇”值来作为考虑的设计标准。但什么是“年最大波高”呢?一年有365天,年最大波高其实是365个“日最大波高”中的最大值,而我们可以假定,365个“日最大波高”近似相互独立,而且具有相同的分布。这就提示我们,在自然界中,有一类物理量,例如年最大波高,它本身就是从若干个独立相同分布的随机变量中选取其最大值形成的。在这种机理下,概率论的理论分析证明,这个最大值分布只可能有三种分布类型。其中应用最广泛的分布应该就是本节要介绍的“最大极值分布”。该分布广泛应用于许多领域,特别是在水文气象学中。龚贝尔(Gumbel)在1958年首次系统全面地分析了这种分布的重要理论价值及实际应用的多种工具和方法,因此这种分布也被称为Gumbel分布。其密度为:
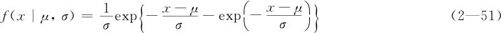
式中,μ是位置参数;σ是尺度参数。μ=0和σ=1的极值分布称为标准最大极值分布,其密度函数图形如图2—50所示。
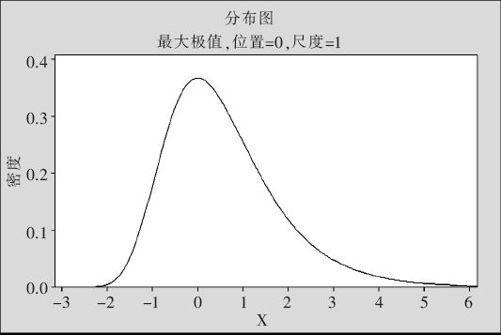
图2—50 标准最大极值分布密度图
最大极值分布的均值和方差分别为:

式中,c是欧拉常数,它是Gamma函数的最小值,大约等于0.5772。
由于最大极值分布在可靠性中也有十分重要的地位,我们将在本书的姐妹篇《基于MINITAB的现代实用统计》(见参考文献[21])的第8章“常用寿命分布及其识别”内做更详细的介绍。
2.3.14 最小极值分布
我们再看另一个自然界中的例子。钢铁材料坚硬无比,在修建各种建筑时要考虑到它究竟可以禁得起多大的拉力而不会断裂?我们可以设想,用力拉钢筋时,什么地方会断裂呢?钢筋中有上亿的分子相互连接着,所谓“断裂”指的就是在这上亿个分子连接中,最薄弱的环节就是能够承受拉力最小的那一段,所以“断裂强度”就应该是承受拉力的最小值。我们可以假定,上亿个分子间能够承受的拉力值是相互独立的,而且具有相同的分布。这就提示我们,在自然界中,有一类物理量,例如断裂强度,它本身就是从若干个独立、有相同分布的随机变量中选取其最小值形成的。在这种机理下,概率论的理论分析证明,这个最小值的分布只可能有三种分布类型。其中应用最广泛的有两种,一种是前面分析过的Weibull分布,另一种就是本节要介绍的“最小极值分布”。最小极值分布广泛应用于许多领域。作为理论上的非常有趣的结果是,如果一个随机变量V服从Weibull分布,那么取自然对数后,即X=lnV应该是什么分布呢?同样经过严格的数学证明,可以断言,X就应该是最小极值分布。
若V服从参数为α和β的二参数Weibull分布,则X=logV就服从尺度参数σ=β-1和位置参数μ=logα的最小极值分布,其概率密度函数是:
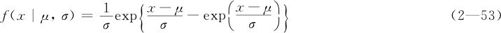
式中,μ是位置参数;σ是尺度参数。μ=0和σ=1的极值分布称为标准最小极值分布,其密度函数图形如图2—51所示。

图2—51 标准最小极值分布密度图
一般的最小极值分布的均值和方差分别为:

式中,c是欧拉常数,大约等于0.5772。
由于最小极值分布在可靠性中也有十分重要的地位,我们将在本书的姐妹篇《基于MINITAB的现代实用统计》(见参考文献[21])的第8章“常用寿命分布及其识别”内做更详细的介绍。
