5.2 基本步骤
假设检验基本步骤的规定在叙述时可以详细也可以简略,我们这里将假设检验过程归结为五个基本步骤。
1.建立假设
假设检验的第一步便是建立假设,通常需要建立一对假设:原假设H0和备择假设H1。比如:在对单总体均值进行检验时,有三类假设:
H0:μ=μ0,H1:μ>μ0
H0:μ=μ0,H1:μ<μ0
H0:μ=μ0,H1:μ≠μ0
称前两个为单边假设检验,后一个为双边假设检验。
在例5—1中,我们用的是单边检验:
H0:μ=2000
H1:μ>2000
假设检验的任务便是根据样本X1,X2,…,Xn来判断原假设是否为真,如果有证据证明它已经不能成立,应该被拒绝,则可以得出结论说我们可以肯定H1是成立的。
2.选择检验统计量,确定拒绝域的形式
若对总体的均值进行检验,那么将用样本均值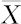 引出检验统计量,若对于正态总体的方差进行检验,将从样本方差S2引出检验统计量。选定检验统计量还要看数据的基本条件,例如是否已知总体标准差σ等。
引出检验统计量,若对于正态总体的方差进行检验,将从样本方差S2引出检验统计量。选定检验统计量还要看数据的基本条件,例如是否已知总体标准差σ等。
根据检验统计量的值,我们把整个样本空间分成两个部分:拒绝域W与接受域A。当样本落在拒绝域中就拒绝原假设,否则就无法拒绝原假设;如果样本落入所谓的“接受域”,我们所能说的也只是“无法拒绝原假设”,因为这时只能说明“目前我们尚未找到证据拒绝原假设”而已,这与说“接受原假设”或“原假设肯定成立”还是有差别的。这时候,拒绝是一种有说服力的判断,而“无法拒绝原假设”是一种没有说服力的判断。所以在假设检验中我们通常总是强调要找出拒绝域。
根据备择假设的不同,拒绝域可以是双边的也可以是单边的。在确定了拒绝域的类型后,还要确定临界值c,这应根据允许犯第一类错误的概率α来确定。
3.给出检验中的显著性水平α
在对原假设是否成立进行判断时,由于样本的随机性,判断可能产生两类错误,如表5—1所示。第一类错误是当原假设H0为真时,由于样本的随机性,使样本观察值落入拒绝域W中,从而做出拒绝原假设的决定,这类错误称为第一类错误,其发生的概率称为犯第一类错误的概率,也称为“拒真概率”,记为α,即P(拒绝H0|H0成立)=α。第二类错误是当原假设H0为假时,由于样本的随机性,使样本观察值落入接受域A中,从而做出无法拒绝原假设的决定,这类错误称为第二类错误,其发生的概率称为犯第二类错误的概率,也称为“纳伪概率”,记为β,即P(不拒绝H0|H1成立)=β。
表5—1 假设检验中的两类错误

由于假设检验的目的通常是要进行某种判断,强调的是判断的说服力要足够强。当原假设成立的时候,如果出现“目前样本观测结果是根本不可能的”,则根据逻辑关系,我们可以根据出现了不应该出现的观测结果,而判定原假设不成立。但现实情况中,当原假设成立的时候,虽然目前观测结果出现可能性很小,但仍然是有可能出现的,则根据逻辑关系,我们“由于目前样本出现了,因而判定原假设不成立”也就有犯了判断错误的可能性。我们要求出现这类错误,也就是犯第一类错误的概率不能超过某个水平α,由此给出的检验称为“水平为α的显著性检验”,称α为显著性水平,通常取α为0.05。
以例5—1为例,因为要求检验钢筋抗拉强度的平均值是否提高,因此H0的要求就是μ=2000,表示平均值并未提高;如果H0:μ=2000被拒绝,则表明钢筋抗拉强度的平均值确有提高。为了真正理解假设检验结论的含义,我们应该具体地理解犯两类错误的实际意义。
关于第一类错误的说明:如果H0钢筋抗拉强度的平均值μ=2000,钢筋抗拉强度的平均值无提高,但我们拒绝了H0,即把钢筋抗拉强度平均值未提高的总体当作了有提高。一般来说就是,当H0成立时,我们却拒绝了H0,这就是第一类错误。犯第一类错误的概率用α表示,通常取α=0.05作为犯第一类错误的概率标准。有时也可能要求犯第一类错误的概率更小,而取α为0.01;有时为了减少犯第二类错误的概率,而取α为0.10。
关于第二类错误的说明:如果钢筋抗拉强度平均值实际已经有提高,但我们却把这样的总体当作了没有提高,没能辨别出来,这种情况下,我们不能拒绝H0,即把钢筋抗拉强度平均值有提高的总体当作了没有提高。一般来说就是,当H0不成立时,我们却未拒绝H0,这就是第二类错误。犯第二类错误的概率用β表示。
在样本量n一定的情况下,α减小,β会增大;β减小,α会增大;要想同时减小α和β,只有增大样本量n才行。
4.给出临界值,确定拒绝域
有了显著性水平α后,可以根据给定的检验统计量的分布,计算或查表得到临界值,从而确定具体的拒绝域。在不同的备择假设下,拒绝域、临界值与显著性水平α的关系是不同的,如图5—1所示。
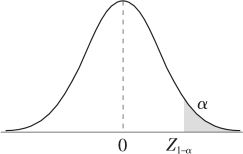
(a)H0:μ=μ0,H1:μ>μ0
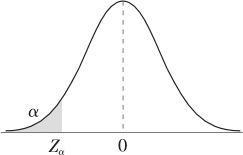
(b)H0:μ=μ0,H1:μ<μ0
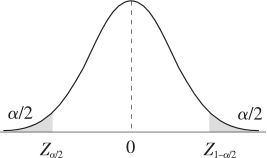
(c)H0:μ=μ0,H1:μ≠μ0
图5—1 备择假设、拒绝域和显著性水平
5.根据样本观察值,计算检验统计量的值并进行判断
判断检验结论通常有三种方法:
(1)p值比较法。所谓p值,指的就是当原假设H0成立时,出现目前状况的概率(严格说是:当原假设H0成立时,出现目前状况或对原假设更不利状况,即对备择假设更有利状况的概率)。当这个概率很小时(例如小于0.05),这个结果在原假设成立的条件下就不该在一次试验中出现;但现在它确实出现了,因此我们有理由认为“原假设成立”的这个前提是错的,因而应该拒绝原假设,接受备择假设。因此可以有个最一般的规则:如果p值<α,则拒绝原假设。所谓p值,也可以理解为“对于此样本拒绝原假设将犯的第一类错误”,因此同样可以得到判断法则:“如果p值<α,则拒绝原假设。”目前大多数统计软件都提供了与假设检验对应的p值(p-value),不必再查统计表确定拒绝域临界值就可以根据p值作出判断结论,这使在假设检验中得出结论的工作大大简化了。那么,小到什么程度才能算很小呢?这与我们指定的显著性水平α有关。我们把p值与显著性水平α进行比较,若p值比α小,则拒绝原假设;反之,不能拒绝原假设H0。实际工作时,通常取α=0.05,我们就把p值与0.05进行比较,若p值比0.05小,则拒绝原假设;反之,不能拒绝原假设H0。
(2)置信区间方法。根据样本观测结果计算总体参数的置信区间,然后看置信区间是否包含了该总体参数的原假设值,如果原假设值未被包含在内,则拒绝原假设;反之,则不能拒绝原假设。目前大多数统计软件都提供了相应的置信区间,不必自己计算,因此用这个方法判断也很方便。
(3)临界值法。这是假设检验最早采用的一种手工计算方法,计算用的工具比较简单。我们先计算出检验统计量的观测值,将它与该检验统计量的临界值进行比较(详细比较方法参见图5—1),当它落在拒绝域中就作出拒绝原假设的结论,否则就作出无法拒绝原假设的结论。
当给定的第一类风险标准α相同时,三种方法得出的结论当然应该是一致的。但它们有不同的侧重点。作为黑带,应该对三者都很熟悉才好,至少前两种方法都应熟练掌握。p值着眼于考虑这个事件出现是小概率事件,其发生的概率是那么小,以至于我们认为它在一次试验中发生是非同寻常的,以此来拒绝原假设;置信区间则着重于考虑原假设的参数值“偏离1-α置信区间有多远”,以此来拒绝原假设。出发点略有不同,结论却是殊途同归。我们分析问题时,应全面掌握这些信息,以便更好地理解所得到的结论。
例5—1续
解 建立原假设和备择假设。
H0:μ=2000
H1:μ>2000
由于钢筋抗拉强度X为正态分布,故的抽样分布也服从正态分布,且标准差已知,检验统计量为:
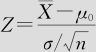
在H0成立时,Z服从标准正态分布。
取显著性水平α,相应检验统计量的拒绝域为右单侧:{Z>Z1-α}(当α=0.05时,式中Z1-α=1.645),即如果Z>1.645,则拒绝H0。
计算检验统计量:
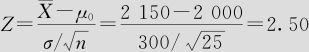
由于Z=2.50>1.645,故拒绝H0。
注:我们这里对例5—1给出的拒绝域的一般形式是Z>Z1-α,此式如果换成Z≥Z1-α,其实结果是一样的(由于连续随机变量形成的统计量恰好取某个指定值的概率肯定为0,可以不予考虑,但对于取离散值的统计量则要小心区别是否包含等号)。
应用MINITAB则可以得到下述结果(操作细节请看本章5.3节):
单样本Z
mu=2000与>2000的检验
假定标准差=300

对于MINITAB输出的结果必须学会解释清楚。这里首先给出样本量n为25,样本均值为2150,均值的标准误(即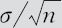 )为60。除此之外,这里主要提供了三处可以直接判断原假设是否成立的计算结果。
)为60。除此之外,这里主要提供了三处可以直接判断原假设是否成立的计算结果。
(1)Z=2.50,应该拒绝原假设。前面对此已经作了分析。
(2)p值=0.006。判断法则是:当p值小于给定的显著性水平α时,则拒绝原假设。本例,p值比0.05小,故应该拒绝原假设。
(3)置信区间。在本例题中,样本均值为2150,总体均值可能稍大些或稍小些,但我们可以有95%的把握来断言,总体的均值一定会大于2051.3(此值就是总体均值的95%置信下限,总体均值的上限是无穷),因为原假设的均值2000比2051.3还小,并未落入此置信区间内,因此应该拒绝原假设。
