9.3 多元线性回归
上节讨论了一元线性回归的情况,其中因变量只与一个自变量有关。在大多数实际问题中,影响因变量的因素往往是多个,我们把这类单个响应变量对于多个自变量的回归问题称作多元回归分析。在本节中,着重讨论最一般的多元线性回归问题,也就是希望得到下列回归方程:

这里一共包含k个自变量。有时也记回归方程所包含的总项数为p,这样就有p=k+1。
多元线性回归分析的基本流程与一元线性回归完全相同,在建立回归方程后,先要进行统计分析,考察模型总效果是否显著,记录回归效果的度量结果,考察各个自变量效应是否都显著,然后进行残差分析。这些分析的结果归纳起来,就是综合考虑并判断:模型与数据拟合得如何?是否模型还有改进的余地?如果模型中有些变量效应不显著,则我们改进时应该删去这些变量;如果在残差分析中,发现残差与响应变量预测值 的图不正常,则要考虑对y作变换;如果在残差分析中,发现残差与自变量x的图不正常,则要考虑增加自变量的高阶项。修改模型后,要再次进行回归分析,看新模型的回归效果是否有改进。如果确有改进,则应该修改原来的模型,然后重新进行统计分析和新的残差诊断,直到获得最满意的模型为止。模型满意后,还要再考虑数据中是否有与模型有较大偏差的点(异常点或强影响点)。如果有这种点,则要考虑如何处理这些点:通常首先要重新检查数据来源或试验条件以及记录中是否有问题,如果确认此数据有问题,则应该删除;如果数据本身并无问题,则要考虑是否换用别的稳健估计方法。
的图不正常,则要考虑对y作变换;如果在残差分析中,发现残差与自变量x的图不正常,则要考虑增加自变量的高阶项。修改模型后,要再次进行回归分析,看新模型的回归效果是否有改进。如果确有改进,则应该修改原来的模型,然后重新进行统计分析和新的残差诊断,直到获得最满意的模型为止。模型满意后,还要再考虑数据中是否有与模型有较大偏差的点(异常点或强影响点)。如果有这种点,则要考虑如何处理这些点:通常首先要重新检查数据来源或试验条件以及记录中是否有问题,如果确认此数据有问题,则应该删除;如果数据本身并无问题,则要考虑是否换用别的稳健估计方法。
与一元线性回归分析不同的是,在多元回归方程中,即使整个回归效果是显著的,因变量y也有可能只与某几个自变量x有密切关系(系数显著不为0),所以对于多元回归,除了检验整个回归方程显著性以外,还要对各个回归系数进行检验,以分辨出哪些x对y没有影响,或者更准确地说,删除了此变量之后对于回归方程没有重要影响。
9.3.1 多元线性回归分析的一般方法
下面,通过一个例题来了解多元线性回归的一般分析方法。
例9—3
某手机厂研究如何提高线路板焊接制程的拉拔力问题。根据过去的经验知道,拉拔力可能与烘烤温度、烘烤时间和涂抹的焊膏量有关,现从制程中收集了20批数据,列入表9—5中(数据文件:REG_拉拔力.MTW)。
表9—5 拉拔力数据记录
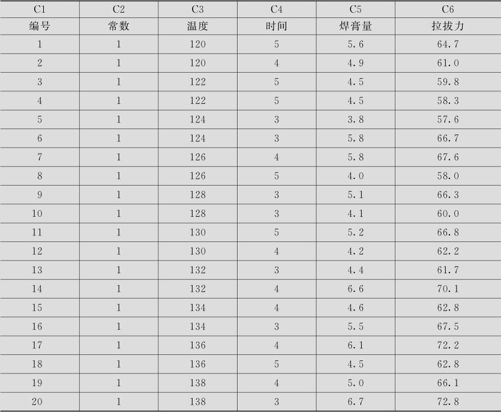
试建立拉拔力与各因素的回归模型。
解 这里有三个自变量,因此本问题是多元回归问题,先建立多元线性回归模型。
建立模型:使用MINITAB软件先打开数据文件“REG_拉拔力.MTW”,选择指令“统计>回归>回归(Stat>Regression>Regression)”,可见到如图9—18所示的界面,输入相应变量名;打开“图形”窗(见图9—18中右上),选择“四合一”及在“残差与变量”中填入各自变量的名称;打开“存储”窗(见图9—18中下),选择“残差”、“标准化残差”及“拟合值”。
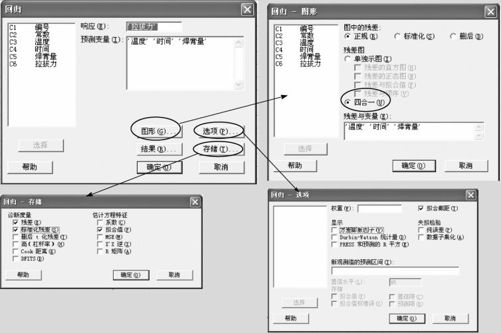
图9—18 多元线性回归操作图(拟合模型)
点击“确定”后,得到以下结果:
回归分析:拉拔力与温度,时间,焊膏量
回归方程为

方差分析


对输出结果的解释:
(1)从ANOVA表分析回归方程总的显著性检验结果,由于p值=0<α=0.05,说明在显著性水平α=0.05下,线性回归方程总效果是显著的。
(2)回归模型显著性的度量指标:从R-Sq=94.7%,R-Sq(调整)=93.7%来看,二者很接近,模型还可以。S=1.146比较小,2S大约2.3,也还可以容忍。
(3)各个回归系数进行显著性检验。在本例中,从回归系数检验来看,自变量“温度”、“焊膏量”的p值都小于α=0.05,故这两个因子均为显著因子;自变量“时间”的p值=0.440>α=0.05,效应不显著,同时在平方和来源中也说明了自变量“时间”的平方和是5.14,在整个平方和中所占比例非常小,所以,这提示我们将来要修正模型时,应删除自变量“时间”。
(4)进行残差分析。先考察四合一残差图(见图9—19):
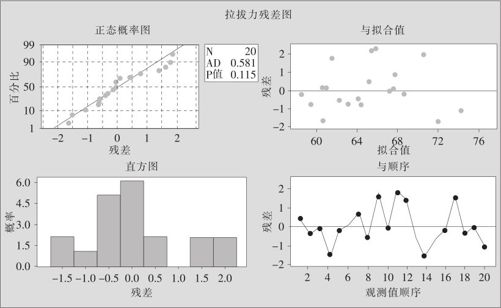
图9—19 四合一残差图
1)残差与数据顺序图(图9—19中右下角),此图正常,残差对于观测值顺序随机分布。
2)残差与拟合值图(图9—19中右上角),此图正常,未看见喇叭口形状分布,说明线性模型是可以接受的。
3)残差的正态概率图(图9—19中左上角),此图正常,数据点基本在一条直线上,即可以认为残差服从正态分布。残差的直方图(图9—19中左下角)也显示了残差的正态性。如果需要准确的检验结果,打开数据文件后可以看见存储的残差,可以对此列进行正态性检验,得到p值=0.115。
4)残差与自变量(见图9—20),这里共有3张图,分别以温度、时间及焊膏量为横轴,都显示残差正常。
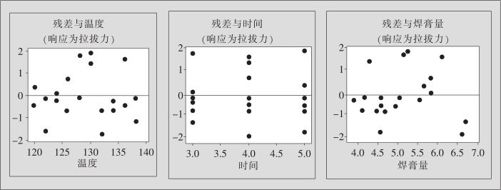
图9—20 残差与自变量图
经过上述分析我们可以认为,设定的线性模型是可以接受的,只是应该从方程中删除不显著变量“时间”。
如果发现在残差对预测值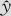 的图中,出现了方差非齐性的情况(即随
的图中,出现了方差非齐性的情况(即随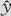 值的不同,呈现“喇叭口”状或弯曲),又该如何处理?我们应该采取对响应变量y进行变换的方法。但如何选择变换的公式呢?此外,为了防止我们用人工方法对残差是否正常的判断中出现失误,也应有工具协助判断此残差图是否有异常,本书在MINITAB之外,提供一个宏指令解决此问题。对于响应变量所采用的变换称为Box-Cox变换,它是以下函数:
值的不同,呈现“喇叭口”状或弯曲),又该如何处理?我们应该采取对响应变量y进行变换的方法。但如何选择变换的公式呢?此外,为了防止我们用人工方法对残差是否正常的判断中出现失误,也应有工具协助判断此残差图是否有异常,本书在MINITAB之外,提供一个宏指令解决此问题。对于响应变量所采用的变换称为Box-Cox变换,它是以下函数:
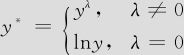
宏指令的名称是Boxcoxregres,它的使用规则是:
(1)数据的存放格式必须是:所有自变量存在连续的若干列中,中间不得有空列;在第一个自变量列的左侧必须有一列全部是1的常数列。
(2)假设响应变量为y,假设常数列存在C2中,其他变量存储于C3~C5,则使用指令“编辑>命令行编辑器(Edit>Command Line Editor)”,在信息窗内输入下列命令(见图9—21):
%boxcoxregres Y C2-C5
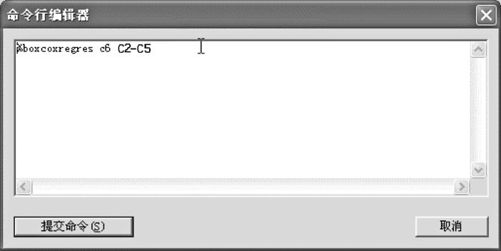
图9—21 宏指令操作图
这里第一个哑元Y是响应变量所在的位置,第二个哑元是自变量存储位置,其中第1列为全是1的常数列,后续是连续排列的自变量观测值。例如,C2是常数列所在的位置,常数列右边是连续排列的自变量数据C3~C7(共5个自变量),则填写“C2-C7”就行了。
本例中,C6是响应变量所在的位置,C2是常数列所在的位置,C3~C5为自变量。
“提交命令”后就可以看见下列图形(图9—22)。
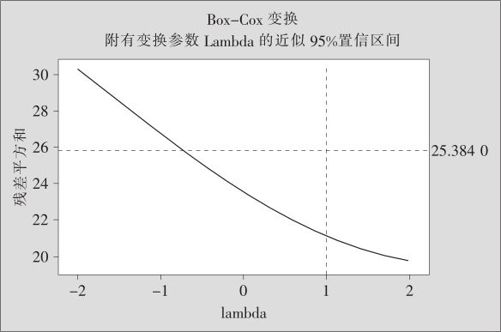
图9—22 宏指令操作结果图
图9—22中的横轴是参数λ(英文为lambda)。对于每个选定的λ,如果以此数值作为y的方幂进行Box-Cox变换,则可以对变换后的数据进行最小二乘法回归,然后可以得到相应的残差平方和,图9—22就是以相应的残差平方和作为纵坐标而绘制出的曲线。当然,残差平方和越小,表示回归效果越好。图形的上方还有一条水平的点虚线,如果曲线落在水平的点虚线之下,则表示对应此范围内λ值都能够满足线性回归模型的条件。对于这张图,主要是考察当λ=1时(即不用变换),曲线是否落在水平的点虚线下方。如果是这样(图9—22就属于这种情况),则表明对于y不必再进行变换,也不必过问λ取为何值将使曲线达到最低;如果当λ=1时,曲线高于水平的点虚线,则表示对于y必须进行变换才能满足回归方程的基本条件。这时应查找能使曲线达到最低点(不必非常准确)的λ值,用此值作为Box-Cox变换的方幂就行了。
综上所述,本回归模型还需要修改,而修改只是要删除不显著变量罢了。
重新进行回归计算,仍从指令“统计>回归>回归(Stat>Regression>Regression)”入口,只是在图9—18中左上图的自变量选取时,删去“时间”,只保留“温度”和“焊膏量”两个自变量,残差分析中,残差对自变量的图中也删去“时间”,其他不变。点击“确定”后,得到相关图形及以下模型修正后结果:
拉拔力的残差与焊膏量
回归分析:拉拔力与温度,焊膏量
回归方程为
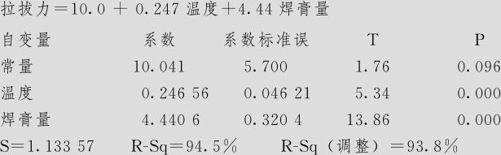
方差分析
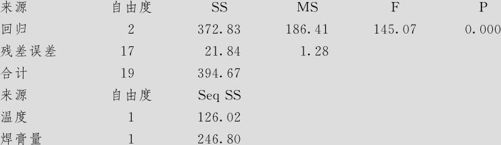
对模型修正后输出结果的解释:
●由对回归方程显著性检验结果(ANOVA输出表),p值=0<α=0.05,说明在显著性水平α=0.05下,回归方程总效应是显著的。
●从回归系数检验输出来看,自变量“温度”、“焊膏量”的p值都小于α=0.05,故这两个因子均为显著因子。
●决定系数R-Sq值为94.5%,说明自变量可以解释响应变量即拉拔力y中94.5%的变异,而修正的R-Sq(调整)为93.8%,与R-Sq更接近(原来是R-Sq=94.7%,R-Sq(调整)=93.7%),这是淘汰“时间”之后的结果(虽然R-Sq值稍有降低)。特别是由原来的S=1.14618降到S=1.13357,证明选取两个变量比保留全部三个自变量效果更好。
●对于单个自变量检验的显著水平究竟取多少为好?通常仍可以使用α=0.05,但由于试验过程中,难免试验误差较大,因此取α=0.10也很常见,甚至有α=0.20的情况,这里并没有严格的统一标准。
●比较回归方程的优劣要看三项指标(R-Sq,R-Sq(调整)及S),如果对于某个方程,其三项指标都好(像本例这样),那在判断上当然就没有问题。如果三项指标不一致怎么办?这时要综合考虑,通常还是看s更有把握些。但有时增多一个自变量即使对方程有改进,但如果改进效果不大,这时并不需要一定选取“最优”的,还是结合实际灵活处理会更好些。
●对模型修正后输出残差图的解释与原来一样,所有图都是正常的(这里从略)。
综上所述,我们可以认为修正后的模型为:
拉拔力=10.0+0.247温度+4.44焊膏量
关于预测等问题这里就不详细叙述了,可以参看9.2.6节。
9.3.2 多元线性回归分析的改进模型方法
例9—3是完全通过正常步骤进行,而且所有结果都是正常状况。当我们发现残差有不正常情况时,一定要认真思考,不要拘泥于任何“准则”,而要根据实际情况灵活处理。例如,首先要考虑回归方程本身的物理意义,根据各变量的实际含义来判断什么样的方程更有价值。有这样一个例子,使用者希望建立圆木体积V与材高H及底部周长C的回归方程。建立线性方程后,发现对自变量的残差有明显的弯曲状况。这时可以根据圆木体积V形成的物理意义,重新考虑方程的样式,设法建立V=a+b1H+b2C2或建立lnV=a+b1lnH+b2lnC这种类型的回归方程会更有意义。下面举例说明残差不正常的处理方法。
例9—4
原木体积估计公式。为了估计森林中仍存活的树木之体积,对于随机挑选的28棵树,先在高度为1.5米处测量其胸径C(单位:米),再用测高仪测出树干高度H(单位:米),伐木后加工为成材原木,测量出其材积V(单位:米3)。希望建立V依赖于C,H的回归方程。数据列在表9—6中(数据文件:REG_原木体积.MTW)。
表9—6 原木体积数据表
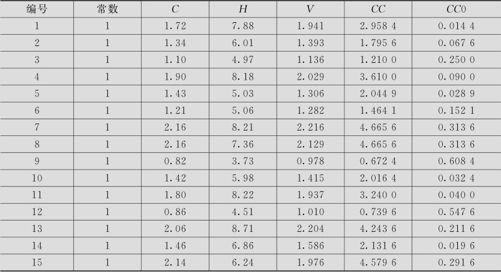
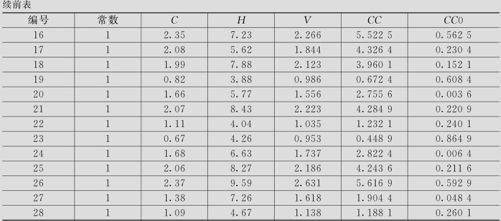
解 这里有两个自变量,先建立二元回归模型(模型1):

操作步骤与例9—3完全相同。输出结果如下:
回归分析:V与C,H
回归方程为
方差分析

此计算结果告诉我们模型总效果是高度显著的,两个回归系数也都是显著的,衡量回归效果的决定系数R2=0.986;调整的决定系数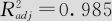 ;一切看来都很好。虽然第26号观测值的残差较大,但由于现在模型尚未最终确定,因此对这个点的问题也只好先不予追究。注意,我们此时并不能立即断定这个回归方程很好,一定要进一步分析残差诊断的结果才能进行判断。
;一切看来都很好。虽然第26号观测值的残差较大,但由于现在模型尚未最终确定,因此对这个点的问题也只好先不予追究。注意,我们此时并不能立即断定这个回归方程很好,一定要进一步分析残差诊断的结果才能进行判断。
其残差四合一图如图9—23所示。残差与自变量图如图9—24所示。
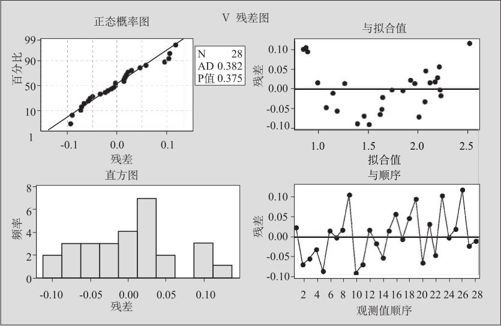
图9—23 残差四合一图
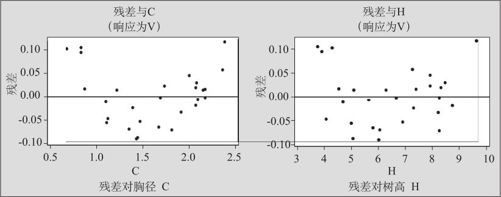
图9—24 残差与自变量图
从残差图上看,残差对响应变量预测值及残差对自变量胸径C都有明显的弯曲(对自变量树高H也有弯曲)。看来模型对于数据的拟合还是有很大问题的,应该再对模型加以改进。对于残差的弯曲,本来可以有两种改进的选择:对Y进行变换(例如将Y开平方或对Y取对数)或者增加自变量高阶项。但我们首先应该从实际问题出发,由于体积大体上是截面积与高度的乘积(可以粗略地设想为圆柱体),因此在本问题中,增加胸径C的平方项是有道理的,因此选择在回归方程中增加自变量的二阶项(模型2):

我们可以把C2当作一个新自变量(记为CC),建立一个三元回归方程。操作步骤与例9—3完全相同。输出结果如下:
回归分析:V与C,H,CC
回归方程为
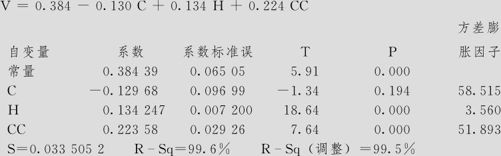
方差分析

从这个计算结果可以看出,模型是显著的,残差图基本上是正常的。但这里包含有不显著的一次项,应该予以删除。模型变成(模型3):

回归方程为:
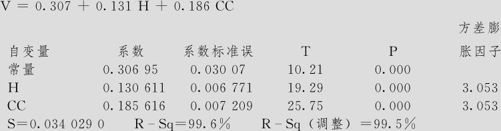
方差分析

回归结果很好,残差图也正常了,分析似乎可以结束了。但是我们很容易想到一个问题,一般来说,C与C2是高度相关的,这会对模型2的求解产生什么影响吗?由于在估计回归系数的时候,实际上是在解一个联立的代数方程组,如果变量间高度相关,相当于此回归系数的方程的行列式接近于0,在解方程时会含有较大的误差。我们下面先研究更一般的问题,即如何处理多元线性回归中各自变量间有显著相关关系的问题。我们首先应考虑如何度量自变量间线性相关的密切程度,再讨论如果有些自变量之间存在密切线性相关时该怎么办。
我们引入方差膨胀因子概念。
将自变量xi与所有其他自变量作回归,设其决定系数为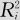 (其定义可以参考式(9—19))。本来在一般的回归问题中,决定系数R2越大说明回归效果越好;但现在是自变量对其余自变量的回归,在自变量间无线性关系时这样的回归方程之决定系数R2应该很小才对,也就是说每个
(其定义可以参考式(9—19))。本来在一般的回归问题中,决定系数R2越大说明回归效果越好;但现在是自变量对其余自变量的回归,在自变量间无线性关系时这样的回归方程之决定系数R2应该很小才对,也就是说每个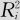 都应该很小。这时若某个R2接近于1,则说明xi有依赖于其他自变量的线性关系(称为有“共线性”),则求解回归系数方程时可能产生较大误差。为度量这种依赖性,引入第i个自变量的方差膨胀因子:
都应该很小。这时若某个R2接近于1,则说明xi有依赖于其他自变量的线性关系(称为有“共线性”),则求解回归系数方程时可能产生较大误差。为度量这种依赖性,引入第i个自变量的方差膨胀因子:
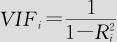
显然,此数值肯定大于1,它越大则说明线性依赖关系越严重(即存在共线性)。通常认为,若VIF<5,则认为共线性不严重;若5≤VIF≤10,则认为有中等程度的共线性,处理时要格外小心;若VIF>10,则认为共线性严重,必须设法解决。解决的办法通常有下面几种方法:增加数据量;变量变换;换用其他方法(主要是岭回归及主成分回归)。
MINITAB软件提供了输出方差膨胀因子的功能,在计算回归结果的操作中(见图9—18中左上图),打开“选项”窗,加选“方差膨胀因子”(见图9—18右下图,图中尚未选此项),即可在每个自变量显著性检验后得到其相应的VIFi值。本例对于模型2输出了VIF栏,其中C及CC项的VIF都远超过10。这就说明,模型中不应该同时引入C及CC项。
一般对于多项式回归方程的改进办法就是使用“正交多项式”,其最简单的形式就是,线性项x不变;二次项改取 ;三次项改取
;三次项改取 ……这里
……这里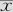 是该自变量所有观测值的平均值。对于胸径C的二次项应该是
是该自变量所有观测值的平均值。对于胸径C的二次项应该是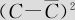 ,我们数据中的胸径C的平均值为1.60,取CC0=(C-1.60)2。
,我们数据中的胸径C的平均值为1.60,取CC0=(C-1.60)2。
下面考虑这样的模型(模型4):
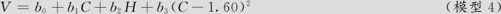
其计算结果为:
回归分析:V与C,H,CC0
回归方程为
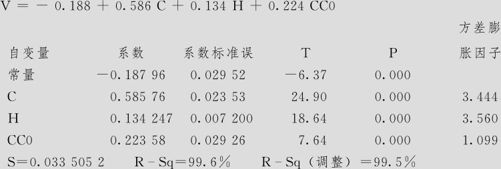
方差分析

由这里的计算结果可以看出,这样取3个自变量后,它们之间并没有严重的共线性问题(方差膨胀因子都小于5),而且它们三个的效应都是显著的,最后回归方程的标准差估计s达到0.0335,它与模型2同样是达到了s最小值,但它避免了模型2中出现的太大的方差膨胀因子,也没有像模型2那样包含不显著的项。可见用模型4这样的方法获得的结果是很好的。
例9—5
在制冷过程中,氨气量非常重要。历史经验表明,氨气的损失量可能与反应过程中的气流、水温及酸浓度相关。现希望求得氨损失量对于气流、水温及酸浓度间的回归方程。数据列在表9—7中(数据文件:REG_氨损失量.MTW)。
表9—7 氨损失量数据表
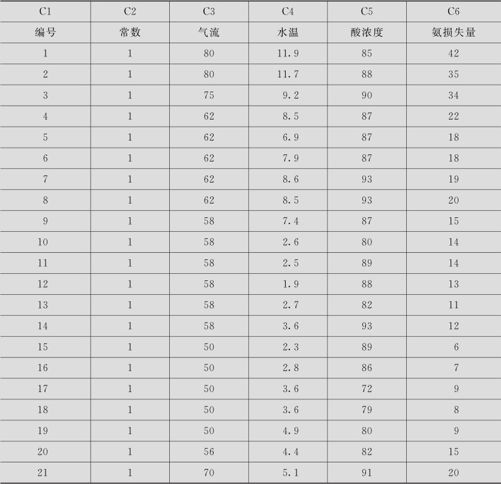
解 这里有三个自变量,因此本问题是多元回归问题,先建立多元线性回归模型,操作步骤与例9—3完全相同。输出结果如下:
结果:REG_氨损失量.MTW
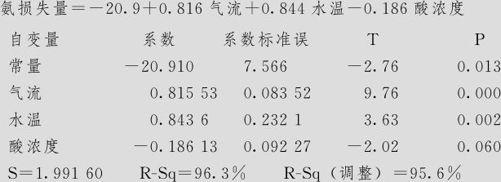
回归分析:氨损失量与气流,水温,酸浓度
回归方程为
方差分析
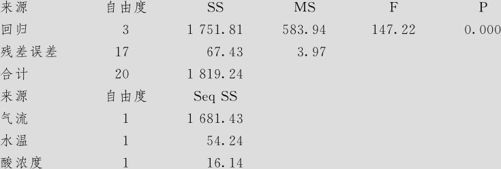
从这里看结果一切正常,回归总效果显著,三个自变量中,“酸浓度”是否保留还可以讨论。但从残差图上看出残差对于拟合值图形不正常(见图9—25中的右上角):残差似乎有“喇叭口”样的发散状况。
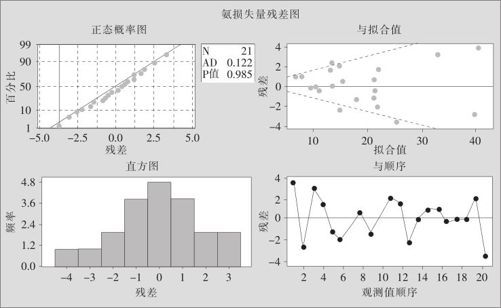
图9—25 氨损失量的回归残差图
这就提醒我们考察一下,此残差图是否真有问题。使用调用宏指令命令:
%boxcoxregres C6 C2-C5
得到下列图形(见图9—26):

图9—26 氨损失量的Box-Cox变换选择图
从图9—26中可以看出,在λ=1时,曲线落在水平的点虚线上方了,这表示对于y必须进行变换才能满足回归方程的基本条件。在图中可以看出,在大约λ=0.5时曲线达到最低,因此我们应该试用求平方根的方法来改进回归方程。这时的回归方程是:

实际计算时,在原数据表中最右侧,再增加生成一列新数据(C7),命名为“平方根”,再对“平方根”这个变量进行回归,其残差图如下(见图9—27):
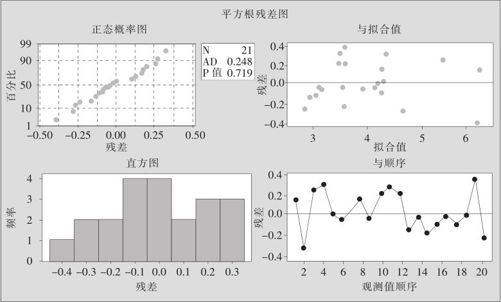
图9—27 氨损失量平方根的残差图
图9—27中的右上图看来已经基本正常了。为了核实这样变换是否确实解决了问题,再次调用宏指令:%boxcoxregres C7 C2-C5,得到下列图形(见图9—28):
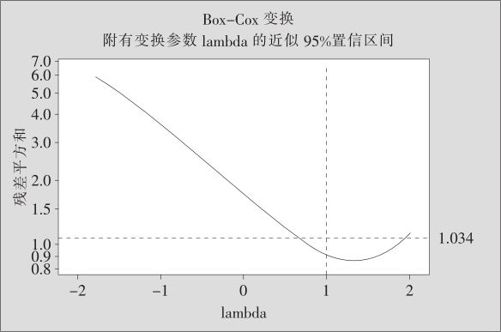
图9—28 氨损失量平方根的Box-Cox变换选择图
从图9—28中可以看出,在λ=1时,曲线确实落在水平的点虚线下方,可见真的解决了问题,表明对于y不必再进行变换了。以下步骤则与以前完全相同,这里就省略了。只是特别要注意,最后方程是式(9—31),要将所有原来对于“平方根”的结果再平方后才能回到“氨损失量”。
如果残差不正常的问题出现在残差对于自变量的图中,则我们应该增加自变量的高阶项。当自变量只有单个时,常可以增加二次项,这就形成二次回归,具体的操作可以从“统计>回归>拟合线图(Stat>Regression>Fitted Line Plot)”入口,再选“二次”,则可以得到二次回归的结果。如果残差仍有弯曲(“S”形或“反S”形),则可以选“三次”,得到三次回归的结果;一般说来,三次回归已经有足够的适应性了。当自变量是多个时,只能使用指令“统计>回归>回归(Stat>Regression>Regression)”,这时可以在数据表中形成你所需要增加的任意类型的高阶项,再选用上述操作,就可以建立对于新的自变量的回归方程了。这里容易出现的一些问题必须注意,详细叙述已在例9—4中给出了。
9.3.3 多元线性回归分析的自变量筛选方法
下面讨论一般的多元线性回归变量筛选问题,这里主要是要考虑自变量之间可能有相关性的情况下可能出现的问题。下面这组数据是著名统计学家哈尔德(Hald)于1952年给出的。
例9—6
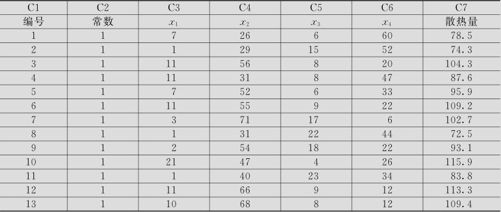
某种水泥在凝固时放出的热量y(卡/克)与水泥中4种化学成分物质x1,x2,x3,x4的含量有关。现记录了13组数据,列入表9—8中(数据文件:REG_Hald数据.MTW),试建立热量y与化学成分间的回归模型。
表9—8 不同成分组合水泥凝固时散热量数据记录
解
方法一:采用一般的多元回归分析方法
建立模型:使用MINITAB软件先打开数据文件“REG_Hald数据.MTW”,选择指令“统计>回归>回归(Stat>Regression>Regression)”,输入相应选项;点击“确定”后,得到以下结果:
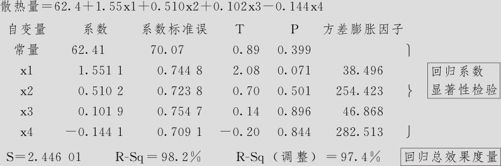
回归分析:散热量与x1,x2,x3,x4
回归方程为
方差分析
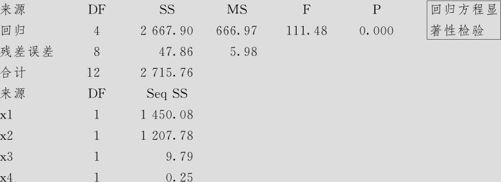
从对回归方程显著性检验结果(ANOVA输出表)来看,p值=0.000<α=0.05,说明在显著性水平α=0.05下,回归方程总效果是显著的。但在本例中,从回归系数检验输出来看,自变量x1,x2,x3,x4的p值都大于α=0.05,都不显著,这是让人吃惊的结果。
怎么可能回归总效果显著,而4个自变量中竟然没有一个是显著的呢?这就牵涉到如何分析各回归变量系数检验结果的问题。在各回归变量系数检验时,粗略地说是“分辨出每个自变量对y是否有显著影响”,其实更准确地说应该是,“删除了此变量之后对于回归方程是否有重要影响”。这一点补充非常重要,当自变量间相互无关的时候,这两种说法几乎相同。但当自变量间密切相关时,由于某个自变量与其他几个自变量密切相关,此变量的效果可以用其他变量的组合来代替,所以删除此变量不会使方程受到多少影响,因而此变量回归系数检验相应的p值会较大。这从方差膨胀因子的数值上可以看出,这里4个自变量的方差膨胀因子都超过5,可见它们之间相关很严重。因此删除一个自变量后,原来的各自变量回归系数检验结果会发生很大变化,所以,不要以为凡是回归系数检验相应的p值较大者就一定不重要。我们不能看见p值大者就一起全部删除,删一个自变量后很可能使留下的自变量的p值发生变化。最后的结论是:由于各自变量间可能相关,因此对于多元回归方程,删除不显著变量时必须逐个进行,删除的顺序仍然是以p值为准,p值越大者越先删除。本例中的所有残差诊断分析都是正常的,这里就不全部列出了。
再回顾一下对各回归系数的检验,其中最大的p值出现在自变量x3上,修正模型时应先删去x3,得到下列结果:
回归分析:散热量与x1,x2,x4
回归方程为
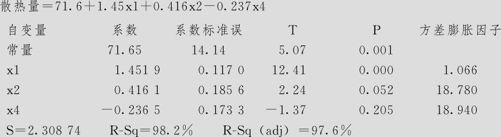
方差分析
删去x3后,x1的p值由不显著(p=0.071)变为显著(p=0.000)了。为什么会这样呢?原因就是自变量间的相关,具体相关关系在9.1节已经给出,我们重复列在下面。
相关:x1,x2,x3,x4

以上相关分析结果说明:x1与x3,x2与x4都高度负相关,原本在4个变量都包含在方程中时,删除任何一个变量对整个方程影响都不大,但删除x3之后,x1就是显著的了;同理,删除x4之后,x2可能就是显著的了。
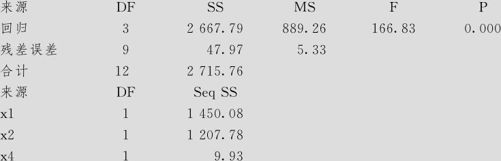
在上述含3个自变量的方程中,总效果仍然显著,由于x4的p值为0.205大于0.05,所以应继续修正模型,删去x4,重复上述过程,得到下列结果(残差分析一切正常,从略):
回归分析:散热量与x 1,x 2
回归方程为
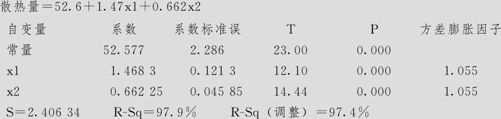
方差分析

最后的结论说明:修正后的模型为:
散热量=52.6+1.47x1+0.662x2
这样逐项删除的方法是人们手工进行多元回归分析必须照办的,但这太麻烦了。当自变量个数达到成百上千时,这几乎无法实现,因此就有了计算机自动筛选的逐步回归分析方法。
方法二:采用逐步回归法
逐步回归分析方法的基本思想就是让计算机自动进行多元回归分析中的自变量筛选工作。逐步回归分析现在已经越来越广泛地应用于各个领域。按怎样的原则和办法来实现筛选的目标呢?通常进行筛选的方法有三种:
(1)“向前选择”(forward selection)。这种“前进法”是:逐个引入自变量,先选入对y影响最大(p值最小)者,再从其余自变量中寻找影响次最大(p值次最小)者,直到无任何变量p值小于指定的“选入α值”可以被引入为止。在向前选择方法中,自变量一旦加进回归模型就不再删除。
(2)“向后消除”(backward elimination)。这种“后退法”是:一开始引入全部自变量,对于p值大于指定的“删除α值”者逐个删除,直至不能再删除为止。
(3)“逐步(向前和向后)”(stepwise(forward and backward))。这种“逐步法”是:自变量逐个引入,边引入边检查已引入自变量中最大的p值是否已大于指定的“删除α值”,若大于,则从模型中删除该项,再重复上述过程。如果没有任何自变量可以删除,则会尝试再加入一个新的自变量,重复上述过程,直至不能再引入也不能再删除为止。
经过统计学家多年的分析证明,这几种方法最终结果可能略有不同,以逐步法为最优。MINITAB软件的相应“逐步回归”功能也只是负责讨论筛选与比较,一旦选中哪些自变量,要再用9.3.2节中介绍的方法进行全面的统计分析。
我们仍以例9—6为示范,说明逐步回归的详细步骤。
(1)建立模型:使用MINITAB软件先打开数据文件“REG_Hald数据.MTW”,选择指令“统计>回归>逐步(Stat>Regression>Stepwise)”输入变量后,在“方法(Methods)”中有三种方法建立模型。
第一种,“前进法”,操作见图9—29。在方法窗内选“前进法”。
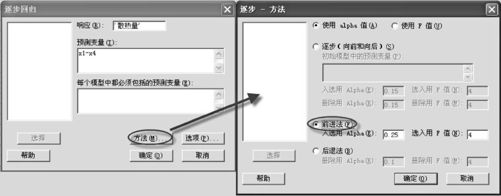
图9—29 逐步回归(前进法)操作图
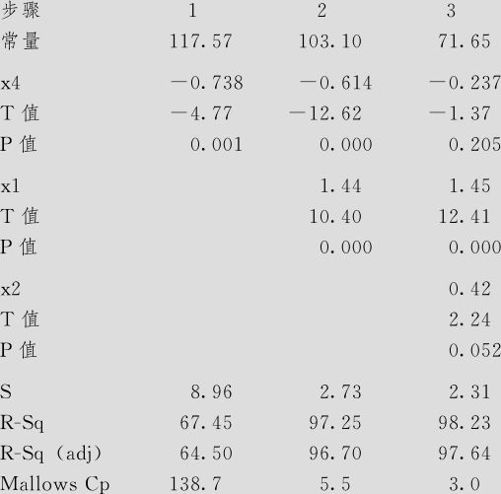
下面是这种方法得到的结果(入选用α值取0.25)。结果的输出中介绍了详细的入选过程,先选入x4,再选入x1,最后选入x2。最终结果是选入这3个自变量。入选用α值换取0.10,结果不变;入选用α值换取0.05,则将只选入x4及x1。
逐步回归:散热量与x1,x2,x3,x4
前进法。入选用Alpha:0.25
响应为4个自变量上的散热量,N=13
第二种,“后退法”。操作见图9—30。在方法窗内选“后退法”。方法是:一开始引入全部自变量,逐个删除,直至不能再删除为止。自变量删除的判定方法是只要某自变量的p值大于“删除用α值”,则将其删除。默认取删除用α值为0.1。这种方法其实与用手算筛选变量方法是一致的。
图9—30 逐步回归(后退法)操作图
采用这种方法得到的结果:先删除x3,再删除x4。最终结果是方程中留下x1及x2这两个自变量。
逐步回归:散热量与x1,x2,x3,x4
后退法。删除用Alpha:0.1
响应为4个自变量上的散热量,N=13

第三种,“逐步法(向前和向后)”。这是标准的也是最好的逐步回归方法。操作见图9—31。在方法窗内选“逐步(向前和向后)”。这里默认入选和删除用α值都为0.15。

图9—31 逐步回归(向前和向后)操作图
逐步回归:散热量与x1,x2,x3,x4
入选用Alpha:0.15 删除用Alpha:0.15
响应为4个自变量上的散热量,N=13
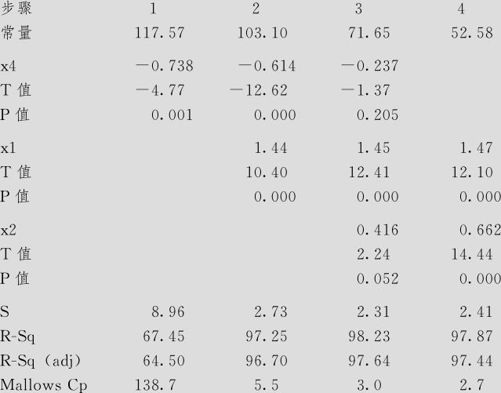
采用这种方法得到的结果:先选入x4,再选入x1,再选入x2,当选入了x1和x2后发现这时x4已经意义不大而应予以删除,因此最后得到的方程中,只含x1和x2。
三种方法结果略有差异,但都是可以使用的结果。并没有绝对的“好结果”或是“劣结果”,通常人们还是愿意采用逐步法计算所得到的结果。
方法三:采用最佳子集法
对于一个实际问题,通常并不能得到一个公认的“最好”的回归方程,采用逐步回归的不同方法也会有不同的结论。为了不漏掉任何一种可能的好结果,我们还可以使用“最佳子集”回归方法,把所有可能的自变量的子集进行回归之结果都列出来,以便使用者综合考虑,从中选出一个最满意的结果。对于究竟在方程内包含多少个自变量,使用者可以任意选定个数的范围;对指定的包含于方程内的自变量个数,可以选定输出最佳的多个方程,选多少个也可以指定。当然,最佳子集回归与逐步回归的作用相同,这里也只提供选择与比较的结果,详细的计算还要用多元回归进行。下面仍以例9—6为示范,说明使用方法。
使用MINITAB软件先打开数据文件“REG_Hald数据.MTW”,选择指令“统计>回归>最佳子集(Stat>Regression>Best Subsets)”;我们只希望得到2~3个自变量的(我们已知只含单个自变量结果很差,含4个自变量结果也不会好),对每种自变量个数都列出4个最佳方程;同时让自变量全部“自由竞争”,不人为规定哪个变量“必须进入”(见图9—32)。
图9—32 最佳子集回归操作图
输入变量后,得到以下结果:
最佳子集回归:散热量与x1,x2,x3,x4
响应为散热量
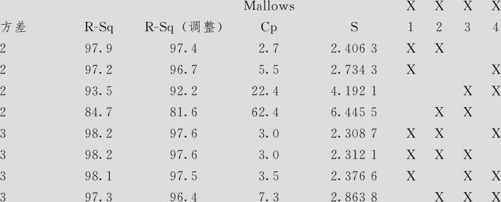
输出结果分析:
我们需要参考R-Sq,R-Sq(调整)(越大且与R-Sq越接近越好),Cp(越接近参数个数越好,包括常数项),s值(越小越好)这几项指标来选取自变量。
本例中,如果决定选2个自变量,则选x1,x2最好;如果决定选3个自变量,则选x1,x2,x4最好。究竟选几个自变量好,可以根据实际需要(考虑精度、计算的方便)来选,并没有绝对好的结果。由于选2个及选3个自变量的标准差相差并不大(选x1,x2,x4时,s=2.3087,只比选x1,x2时,s=2.4063的结果好一点点),所以我们最终可以选取x1,x2两个变量。然后借用指令“统计>回归>回归(Stat>Regression>Regression)”,自变量输入x1,x2,最后会得到有关的全部结果。
综上所述,用最佳子集回归和用逐步回归方法都可以协助使用者选定较好的回归方程。逐步回归方法提供了详细的筛选过程,可以看见各自变量重要性的比较,其中以逐步法为最好;后退法次之;前进法效果最差。最佳子集回归只提供了最后结果,它比逐步回归法优越的是可以提供全部可能的选择,不会漏掉好的结果。两种方法各有其优缺点,都可以采用。
